Дослідження прихованої канібалізації в Google Ads на сирих даних e-commerce акаунту: 16 місяців історії, 2.24 мільйона рядків search terms, чотири переглянуті гіпотези.
Чому я взялась за це дослідження? Я бачу як змінюється підхід ШІ всередині Google Ads. Поки ще працював Smart Shopping, Performance Max був зовсім сирий — у 2024 році в PMax можна було гарно тестувати різні аудиторії в сигналах з тими самими товарами, і кампанії реально рухалися у різні боки. Алгоритм орієнтувався в першу чергу на аудиторію — і це працювало.
З 2025 року я побачила що підхід почав мінятися. До кінця 2025 PMax-алгоритм працює зовсім по-іншому. Аудиторні сигнали мають все менше ваги, алгоритм все сильніше дивиться на сигнали з усього акаунту і самостійно вирішує куди йде трафік. Старий підхід “запустимо дві PMax з різними audience signals, щоб ловити різні аудиторії” перестав працювати — а частина рекламодавців продовжує тестувати аудиторії так наче на дворі 2024 рік.
І коли клієнти приходять до мене на аудит — типова помилка яку я бачу: один і той самий товар знаходиться у двох PMax-кампаніях. Підхід зберігся з часів коли він мав сенс. Зараз — не має. Але переконати рекламодавця у цьому абстрактними аргументами складно. Тому це дослідження — на цифрах, на сирих даних одного з акаунтів, чому така структура зараз шкодить.
В акаунті, який я нещодавно прийняла на аудит, я помітила знайому картину: один і той самий ідентифікатор товару показувався у двох різних PMax-кампаніях одночасно. Поряд із рідним айдішником `SKU_25570` у звіті стояв `df_SKU_25570` — той самий товар, але з модифікованим ID через дублювання фіда товарів у Merchant Center. Дві Performance Max-кампанії бачили один SKU, обидві крутили на ньому рекламу.
Цей патерн поширений в e-commerce кабінетах. Аккаунт-менеджери свідомо створюють “дублікат фіда” з префіксом `df_` саме для того, щоб обійти технічне обмеження “один SKU = одна кампанія” і запустити другу PMax на ту саму товарну позицію. У індустрії існує три типові виправдання чому це роблять:
- Сегментація аудиторій — мовляв, дві кампанії “ловлять” різні сегменти покупців: одна тих хто шукає дешевше, інша дорожчих клієнтів.
- Хеджування ризиків — якщо алгоритм в одній кампанії “зламається” або втратить навчання, друга підстрахує.
- Прихований A/B-тест — порівняти різні tROAS, різні audience signals, різні набори assets на тих самих товарах.
Кожне з цих виправдань звучить раціонально. Але вони базуються на припущеннях про те як насправді поводиться алгоритм Performance Max коли стикається з двома кампаніями того самого акаунту, що конкурують за один SKU. Я хотіла перевірити це на сирих даних.
Питання дослідження було простим: чи дві PMax на один товар канібалізують одна одну на аукціоні? Якщо так — як саме і скільки це коштує? Якщо ні — можливо, цей патерн насправді корисний для бізнесу?
Спойлер: відповідь виявилась складнішою, ніж будь-який з трьох сценаріїв які я очікувала.
Дані і методологія
Дослідження проведено на e-commerce акаунті в категорії товарів для дому. Період даних — 16 місяців: 30 грудня 2024 → 20 квітня 2026. Я не вестиму цей акаунт публічно, тому замість назв реальних кампаній використовую нейтральні позначення: PMax A — стара кампанія, працювала весь період; PMax B — нова, стартувала всередині періоду.
Дані
Витяг з Google Ads зробила у п’ять окремих експортів через ліміт рядків Google Ads. Об’єднала і очистила:
- Звіт по товарах в Покупках — 1.65 мільйона рядків. Сегментація: кампанія × тиждень × ID товару. 22 PMax-кампанії, з них на аналіз пішло три. ~30,000 унікальних SKU.
- Звіт по пошукових термінах — 2.24 мільйона рядків. Той самий період і ті самі три кампанії. 245,000 унікальних search terms.
- Історія змін кампаній — 986 записів змін tROAS, бюджетів, статусів за 16 місяців. Критично важливо для контролю конфаундерів.
Числа я очистила від європейської локалі (десяткова кома, пробіли в числах, лапки), нормалізувала item_id (зрізала префікс `df_` від дублікатів фіда), відфільтрувала тільки ті SKU що належать аналізованому домену (89.8% всіх рядків — решту викинула як товари інших сайтів кабінету).
Методологічні пастки які я закривала
Це моє четверте дослідження PMax-алгоритму на сирих даних. У попередніх трьох я наступила на чотири пастки які зруйнували перші висновки. Тут я закривала їх свідомо ще до запуску аналізу:
Пастка 1 — формат item_id
ID товарів у двох фідах можуть мати різні префікси. У моєму випадку 4,642 з 9,631 SKU мали префікс `df_` (дублікат фіда). Без нормалізації матчинг shared SKU давав би 12% замість реальних 50%. Перевірка: для всіх 2,375 SKU що мали обидві версії, Merchant Center ID у `df_X` і `X` співпадає. Тобто `df_X` і `X` — це один і той самий товар з одного MC, лише з модифікованим ID.
Пастка 2 — selection bias
Якщо групувати SKU за їх активністю після стартової події — Google сам обирає топ-SKU для другої кампанії, і “ефект кампанії” виявляється selection bias. Я фіксую групи SKU за pre-period активністю (до моменту старту другої кампанії), а потім дивлюся як кожна група поводиться після.
Пастка 3 — конфаундери з історії змін
Конфаундер — це фактор який змінюється паралельно з тим що ми досліджуємо, і через це може створити ілюзію причинно-наслідкового зв’язку. Простий приклад: якщо я хочу виміряти ефект старту другої PMax на CPC, і саме у цей же тиждень підняли tROAS у першій кампанії — стрибок CPC можна списати на що завгодно з цих двох змін. Це і є конфаундер.
Будь-яка зміна tROAS, бюджету, фільтру товарів за період аналізу створює конфаундер. Я витягнула повну change history по всіх трьох кампаніях. Результат показав 89 критичних змін (tROAS, бюджет, статус) за 17 місяців у одній парі. У вікні ±6 тижнів навколо стартової події — 40 змін. Це не “чистий природний експеримент”, і це треба чесно зазначити.
Пастка 4 — life cycle товарів
У попередньому дослідженні топ-50 SKU виявилися конкретним жанровим трендом який природно охолоджувався. “Просадка PMax” виглядала як алгоритмічний ефект, але була demand cycle. Перш ніж робити висновки, я подивилась на топ-20 shared SKU за конверсіями — це евергрін-каталог декору для стін з постійним попитом, не сезонні позиції.
Дизайн дослідження
Я зосередилась на двох парах кампаній з найбільшими витратами на shared SKU:
- Пара A (longitudinal): PMax A (стара, працювала >12 місяців) і PMax B (нова, стартувала всередині періоду). 21 тиждень спільної історії. Reference event = тиждень старту PMax B. Дозволяє порівняти “до” і “після” появи другої кампанії.
- Пара B (cross-sectional): PMax A і ще одна стара кампанія, яка працювала весь період. 68 тижнів спільної історії. Тут немає ref event — порівнюю shared vs solo SKU всередині періоду. Слугує як перевірка висновків з пари A на незалежних даних.
Третій тестовий кандидат на longitudinal-порівняння виявився непридатний — кампанія працювала на іншому форматі ID (без характерного суфікса домену), тож SKU не матчились з нашими. Викинула.
Один з ключових методологічних виборів — порівнюю тільки одні й ті самі юніти. Не “shared SKU vs solo SKU” (це різні групи товарів з різними характеристиками), а “той самий SKU у двох кампаніях у той самий тиждень”. Це закриває третій важливий шар selection bias.
Інсайт 1: дві PMax піднімають ставку одна одній на тих самих запитах
Перше що я хотіла з’ясувати — чи кампанії взагалі ловлять одні й ті самі пошукові запити. Може Google всередині розводить їх на різні аукціони (одна на категорійні запити, інша на бренд, наприклад)? Якщо так — канібалізації немає за визначенням.
Я порахувала перетин search terms між PMax A і PMax B у post-period — після того, як друга кампанія стартувала. Результат:
- Унікальних search terms у PMax A: 88,027;
- Унікальних search terms у PMax B: 35,496;
- Перетин: 31,552 — це 88.9% від меншої кампанії.
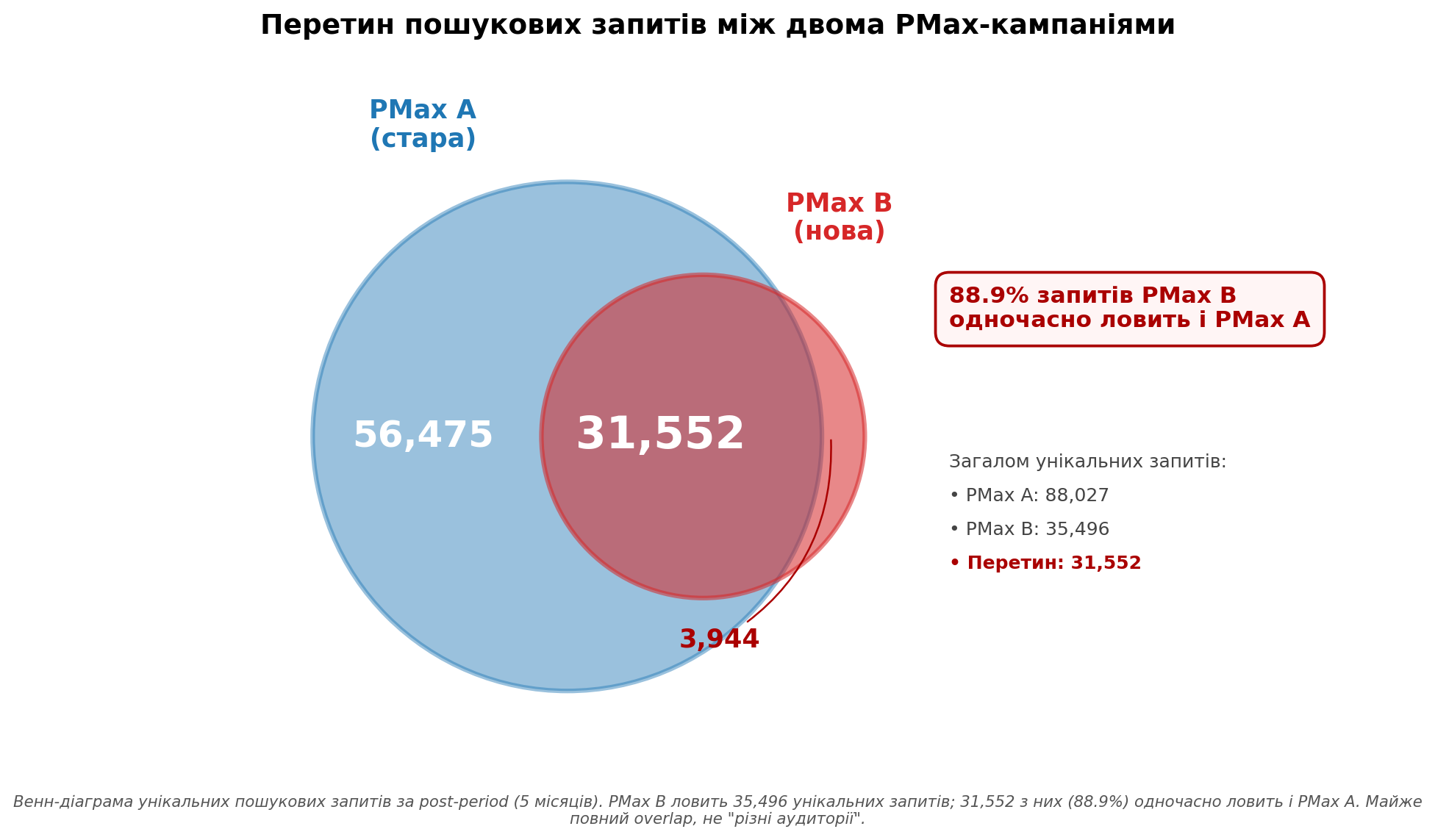
Графік 1. Венн-діаграма перетину пошукових запитів. Майже всі запити які ловить PMax B одночасно ловить і PMax A.
88.9% запитів які ловить PMax B одночасно ловить і PMax A. Це не “різні аудиторії” — це майже повний overlap. Гіпотеза що Google розводить кампанії на рівні запитів — відкидається.
Далі — головний тест. На запитах де обидві кампанії отримали клік у тому самому тижні, я порівняла CPC. Якщо алгоритм Performance Max ефективно розводить кампанії на рівні аукціону — CPC у двох кампаніях має бути приблизно однаковий. Якщо вони конкурують одна з одною — ставка слабшої буде вище.
Що показує CPC на overlap-запитах?
4,386 пар “запит × тиждень” де обидві кампанії отримали клік. Зважений CPC (зважено за кліками):
- PMax A: 1.73 PLN;
- PMax B: 3.01 PLN;
- Різниця: PMax B на 74% дорожчий.
На 58% спостережень PMax B дорожчий за PMax A на той самий клік. Розподіл нерівномірний — у хвості (P90) PMax B платить у 3.6 рази дорожче, у P95 — у 6 разів дорожче. Це не “шум”. Це чіткий патерн bid escalation: коли два бідери одного акаунту лізуть в один аукціон, ставка піднімається.
Ще цікавіше — як цей патерн залежить від об’єму запиту. Я розбила overlap-запити на 5 сегментів за кількістю кліків які отримала PMax B:
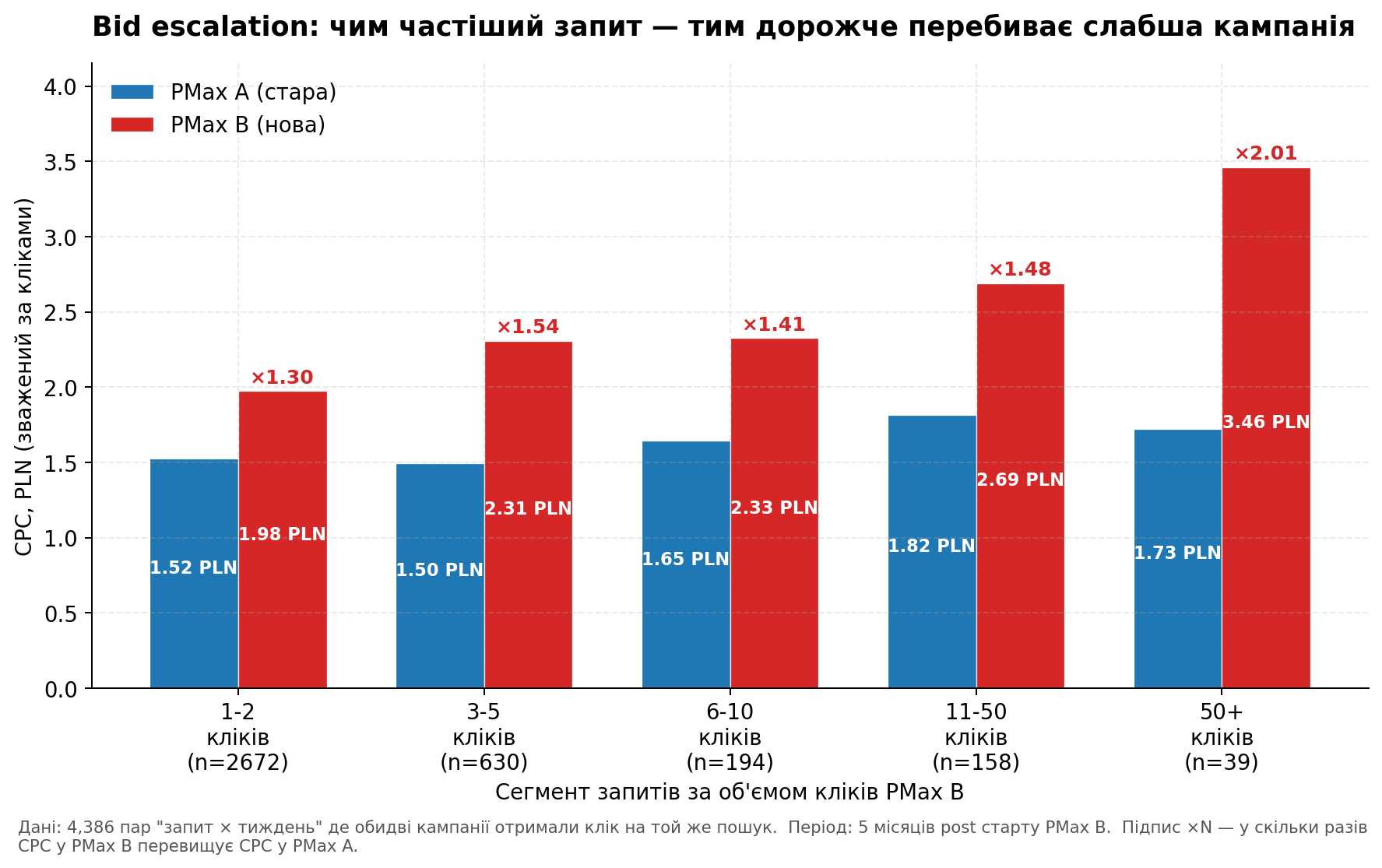
Графік 2. Bid escalation за об’ємом запитів. На рідкісних запитах (1-2 кліки) PMax B платить +30%; на топ-запитах (50+) — у 2 рази дорожче.
Чим інтенсивніший аукціон, тим вищий податок за подвійну участь. На рідкісних запитах (1-2 кліки на тиждень) PMax B переплачує помірно — +30%. На середніх — +40-55%. На топ-запитах де йде багато трафіку (50+ кліків на запит на тиждень) PMax B платить вже у 2 рази дорожче за PMax A.
Що я маю на увазі під “податком за подвійну участь”. Коли в одному аукціоні Google дві кампанії одного акаунту, алгоритм мусить вибрати між ними — і робить це через підняття ставки. У результаті обидві кампанії заплатять більше ніж заплатив би один учасник. Ця надбавка — це і є податок: гроші які акаунт віддає Google виключно за факт того що в нього в системі дві кампанії на той самий товар, а не одна.
Це класична економіка аукціону: коли в аукціоні одна сторона з агресивною ставкою, друга змушена піднімати свою, щоб не зникнути з показів. У звичайних умовах це механізм цінотворення між незалежними рекламодавцями. Тут це механізм цінотворення між двома кампаніями однієї й тієї ж компанії, які не мають жодних причин конкурувати між собою — окрім того що вони існують паралельно.
Висновок 1: чим частіший пошуковий запит, тим сильніша канібалізація. На топ-запитах CPC слабшої кампанії доходить до 2x. Це не “Google розводить кампанії на різні запити” — це Google пускає обидві в той самий аукціон і збирає вищу ставку.
Чому це збігається з тим що бачать практики?
З моєї практики: типова поведінка PMax — якщо в акаунті крутиться сильний товар у двох PMax-кампаніях, одна з них завжди дорожча. Це бачу постійно. Bid escalation — феномен який практики PPC бачать на власних акаунтах роками. Просто тепер він виміряний.
Друга важлива деталь — PMax не ізолює кампанії на рівні search terms. У довідці Google написано прямо: алгоритм враховує сигнали з усього акаунту коли вирішує який запит назначити до якого об’єкта. Тобто дві PMax — це не “дві воронки” з власними воронками запитів, а два пасма однієї матриці. І у тих місцях де ці пасма перетинаються — алгоритм піднімає ставку до того рівня, який обидва готові платити.
Інсайт 2: міф про сегментацію аудиторій
Найпоширеніше виправдання двох PMax — “одна ловить дешевших клієнтів, друга — дорожчих, аудиторії розділені”. Це звучить переконливо: якщо PMax B ловить клієнтів з вищим середнім чеком, то навіть переплата за CPC виправдана — value більший.
На своїх перших ітераціях аналізу я була близька до підтвердження цієї тези. У PMax B на overlap-запитах AOV (середній чек на конверсію) виявився 1,150 PLN проти 707 PLN у PMax A. Майже у 1.6 разів вище. Я навіть на хвилину подумала що знайшла позитивний ефект дублювання — “PMax B ловить дорожчих клієнтів”.
Але я пішла глибше і знайшла нюанс. Загальне середнє AOV ховало розподіл за об’ємом запитів. Якщо порахувати окремо по сегментах — картина може виявитись зовсім іншою.
Я розбила overlap-запити по volume bucket і подивилась AOV у кожному:
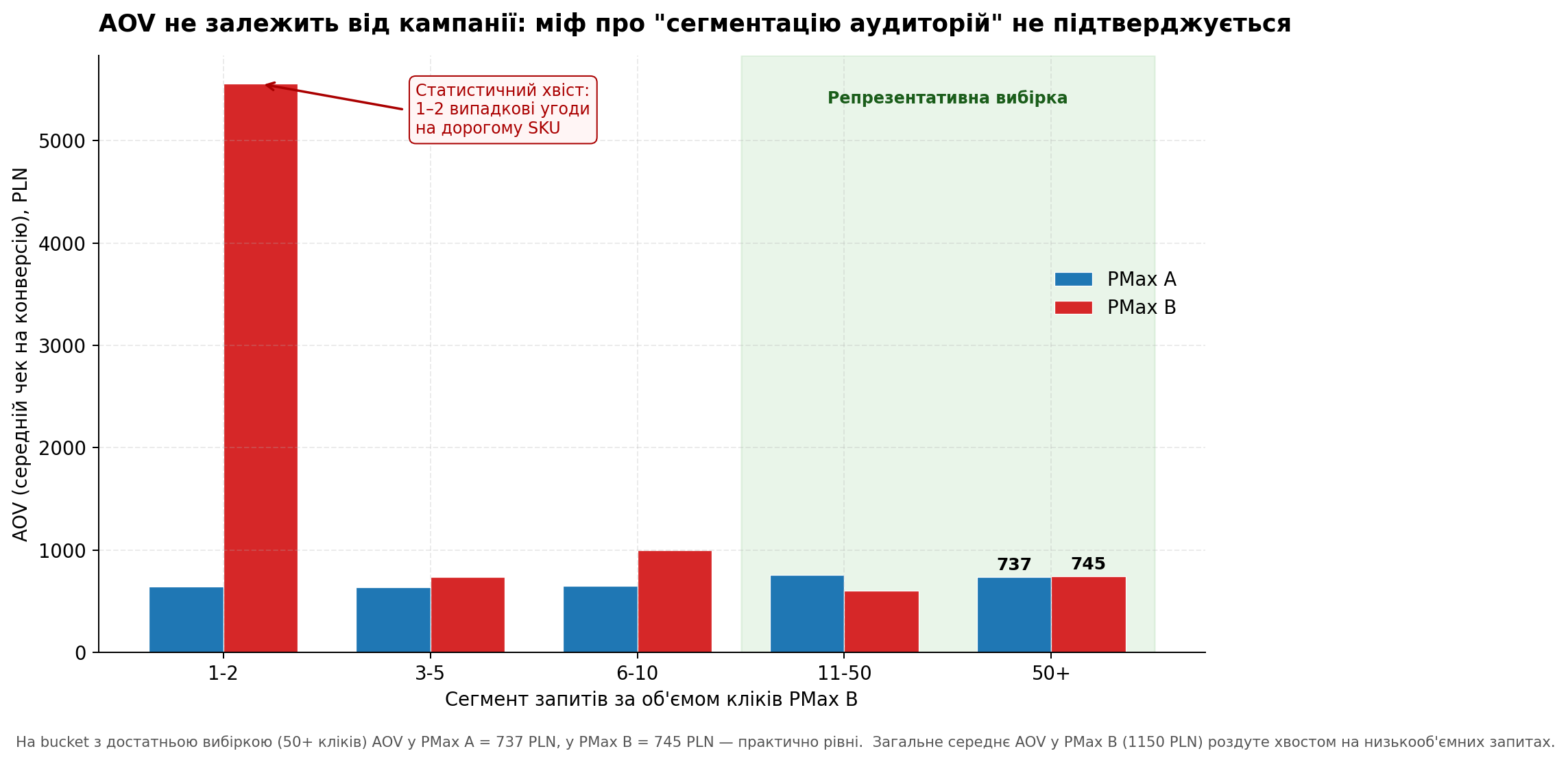
Графік 3. AOV за сегментами запитів. На репрезентативній вибірці (50+ кліків) AOV у двох кампаній практично рівний.
Картина повністю змінилась. На bucket з достатньою вибіркою (50+ кліків — найбільш репрезентативний сегмент) AOV у PMax A = 737 PLN, у PMax B = 745 PLN. Практично рівні.
Загальне середнє AOV = 1,150 PLN у PMax B виявилось повністю результатом хвоста на bucket 1-2 кліки. Там одна-дві випадкові угоди на дорогому SKU (середній чек ~5,500 PLN) роздули середнє по групі. Якщо викинути цей хвіст — жодної реальної “сегментації аудиторій за чеком” між двома PMax немає.
Висновок 2: міф про “сегментацію за дорогими і дешевими клієнтами” не підтверджується. AOV вирівнюється до середнього по ніші незалежно від того яка з двох PMax-кампаній зловила покупця.
Це методологічно важливий момент. У статистиці є відомий ефект: на маленькій вибірці середнє завжди буде нестійким. Один великий замовник на 5,000 PLN перетворює групу з 10 кліків на “сегмент з високим AOV”. Якщо менеджер подивиться на агреговану цифру по PMax B — побачить уявну перевагу. Якщо подивиться на розподіл по сегментах — побачить що це артефакт.
Це і є фундаментальна проблема того як PPC-фахівці часто оцінюють кампанії: “середнє AOV у кампанії X”. Коли кампанія має нерівномірний розподіл об’єму між запитами (а у PMax це майже завжди так — 80/20), середнє по кампанії не репрезентативне. Воно зважене саме хвостом.
Що це означає для теорії “різних аудиторій”?
Якщо AOV однаковий, два логічних висновки:
- Performance Max не “сегментує” клієнтів за платоспроможністю. Алгоритм усередині того самого пошукового запиту (“категорійний запит”) направляє трафік у різні кампанії, але не за “типом покупця”, а за іншими сигналами (audience signals в кампанії, креативи в asset groups, landing page). Сам пул аудиторій який бачить кожна кампанія — однаковий.
- Це означає що у двох PMax немає реальної “продуктової логіки” сегментації — є лише штучна, через дублювання фіда. У результаті дві кампанії конкурують за той самий пул покупців з тими самими середніми чеками — просто з різними наборами assets.
Це і є той момент де теорія “корисного дублювання” розпадається. Якщо AOV однаковий, тоді все що відбувається — це bid escalation з Висновку 1, який не приносить додаткової value, лише збільшує витрати акаунту.
Інсайт 3: реальний CPA на покупця завищений на 21%
Тут я зробила найсерйознішу методологічну помилку у перших ітераціях, і ось як її довелось виправити.
Спочатку я порахувала CPA окремо в кожній кампанії на overlap-запитах:
- CPA у PMax A на overlap: 340 PLN;
- CPA у PMax B на overlap: 334 PLN.
“Майже однаковий”. Я зробила висновок що дві кампанії економічно нейтральні — переплата за CPC у PMax B (+74%) компенсується вищим CR (вдвічі), і у підсумку вартість залучення покупця однакова. Дублювання здавалось безкоштовним.
Але дивитись на CPA так — як на простий показник окремої кампанії — некоректно для нашого випадку. Я дивилась на CPA так, наче клієнт зайшов з одного кліку і одразу купив. Але насправді у цьому акаунті атрибуційний шлях — 3.5 взаємодій / 2.6 дні до покупки. Тобто на одну конверсію припадає в середньому 3.5 кліки. І коли в акаунті дві PMax-кампанії на ті самі пошукові запити, ці 3.5 кліків розкидані між двома кампаніями. Тут треба рахувати не CPA окремої кампанії, а CPA на покупця у сумі.
Уявімо реальний шлях клієнта: він бачить рекламу за запитом “категорійний запит + специфікатор” і клікає (PMax A). Через день шукає знову за запитом “категорійний запит + приміщення” і клікає (PMax B). Через ще день шукає бренд і клікає знову (PMax A). Потім купує. Хто “привів” цю конверсію? У data-driven attribution — обидва. Кожна кампанія записує собі частину конверсії. У звітах: PMax A заплатила 5 PLN за ту конверсію, PMax B заплатила 6 PLN, кожна показує адекватний CPA.
Але реальна вартість конверсії = 11 PLN. Це сума того що дві кампанії заплатили щоб привести одного покупця. І це число ніде у звіті Google Ads не бачено.
Як я порахувала реальний CPA?
На overlap-запитах за 5 місяців post-period:
Метрика | Значення |
Сумарні витрати (PMax A + PMax B) | 116,233 PLN |
Сумарні конверсії (обох кампаній) | 494 |
Реальний CPA на покупця | 235 PLN |
Сумарна value (обох кампаній) | 427,514 PLN |
Сумарний ROAS | 3.68 |
Реальний CPA = 235 PLN. Не 340 і не 334 які видно у звітах. 235.
Тепер контрфактне порівняння. Що було б якби лише PMax A ловила ці запити? Конверсії все одно б відбулись — клієнт шукає категорійний запит на тому ж сайті, з тим самим товарним каталогом. Він би клікнув по PMax A замість PMax B на одному з кроків шляху, і прийшов до тієї самої покупки. Витрати були б нижчі, бо CPC у PMax A на overlap-запитах = 1.73 PLN, тоді як у PMax B = 3.01 PLN.
Розрахунок:
- Сумарні кліки overlap: 51,428;
- CPC у PMax A на overlap: 1.87 PLN;
- Контрфакт cost (всі кліки за CPC PMax A): 95,996 PLN;
- Конверсії (припускаємо ті самі): 494;
- Контрфакт CPA: 194 PLN.
Різниця між фактичним і контрфактним CPA = 41 PLN на кожну конверсію. У відсотках — 21% завищення.
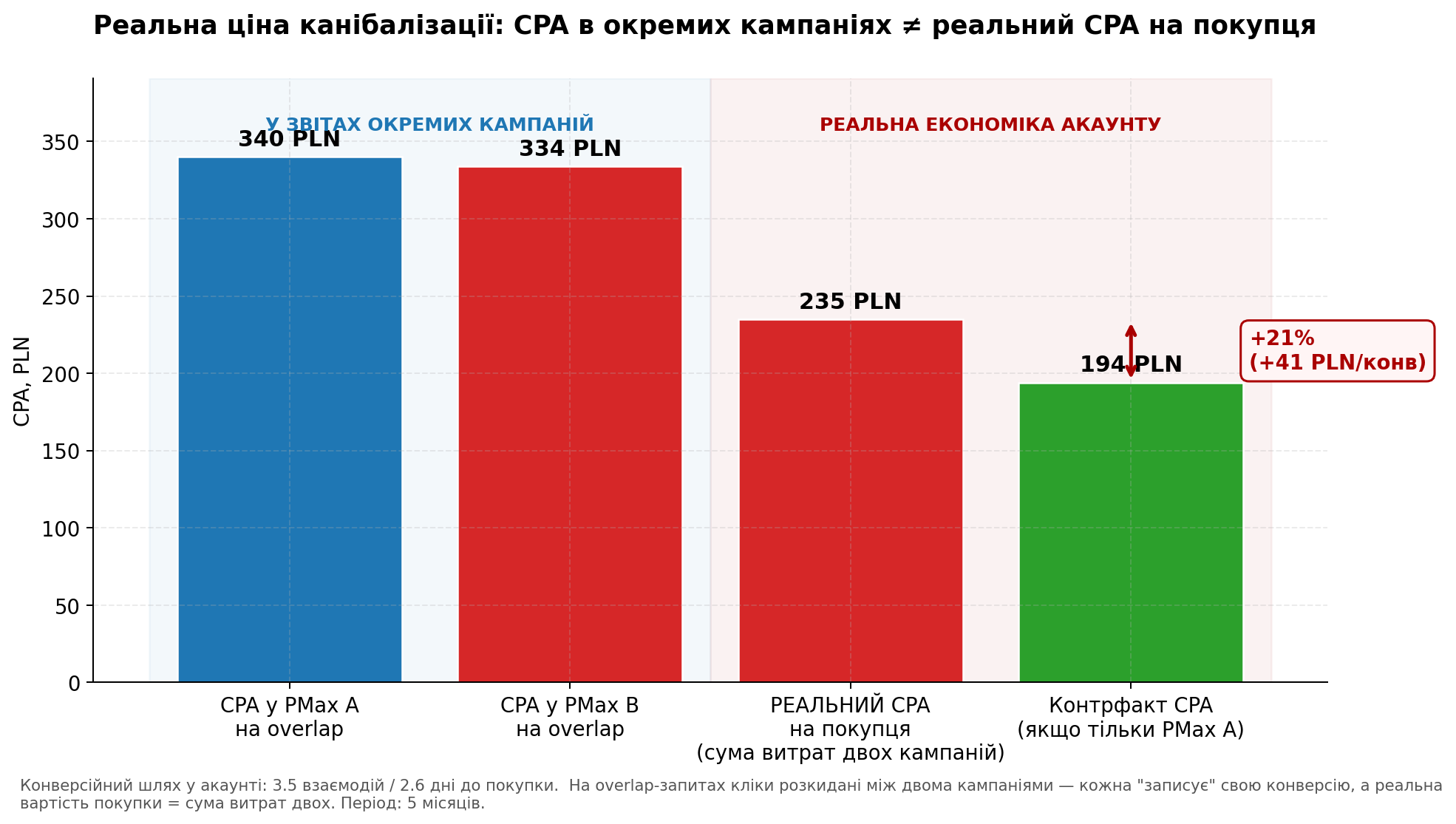
Графік 4. CPA в окремих кампаніях (340 і 334 PLN) виглядає однаковим. Реальний CPA на покупця, з урахуванням сумарних витрат двох кампаній — 235 PLN. Контрфакт без дублювання — 194 PLN. Різниця +21%.
Висновок 3: канібалізація завищує реальний CPA на покупця на 21%. У звітах окремих кампаній цього не видно — там показники виглядають нормальними. Завищення помітне тільки якщо рахувати сумарну економіку акаунту по ключових SKU.
Чому ця помилка така типова?
Я роблю цю помилку не одна. Це базовий спосіб дивитись на ефективність кампаній: відкрив звіт по кампанії — побачив CPA. Якщо CPA у межах KPI — кампанія здорова.
Але це працює тільки коли кампанії незалежні. Якщо вони ділять одну і ту саму базу клієнтів — кожна показує “свою” частину тих же конверсій, і CPA індивідуально виглядає чесним. Сума ж витрат на одного реального покупця — невидима.
Чим коротший атрибуційний шлях, тим менш помітний ефект. Якщо в акаунті атрибуція 1.2 взаємодії на конверсію — переплата буде ~5%. Якщо 3.5 — як у нашому випадку, 21%. Якщо 5+ — може бути 35%+.
На маленьких бюджетах і складних шляхах конверсії здорожчання навіть більше за 21%. Дві PMax-кампанії на одну і ту саму нішу зашивають у CPA приховану надбавку, яку акаунт-менеджер не бачить — бо в окремій кампанії показники виглядають нормально.
Сумарна переплата у часі
Я порахувала тижневу переплату на overlap-запитах. Формула: cost_PMax_B − (clicks_PMax_B × CPC_PMax_A на тому ж запиті). Тобто скільки PMax B заплатив понад те, що PMax A заплатила б за ті самі кліки.
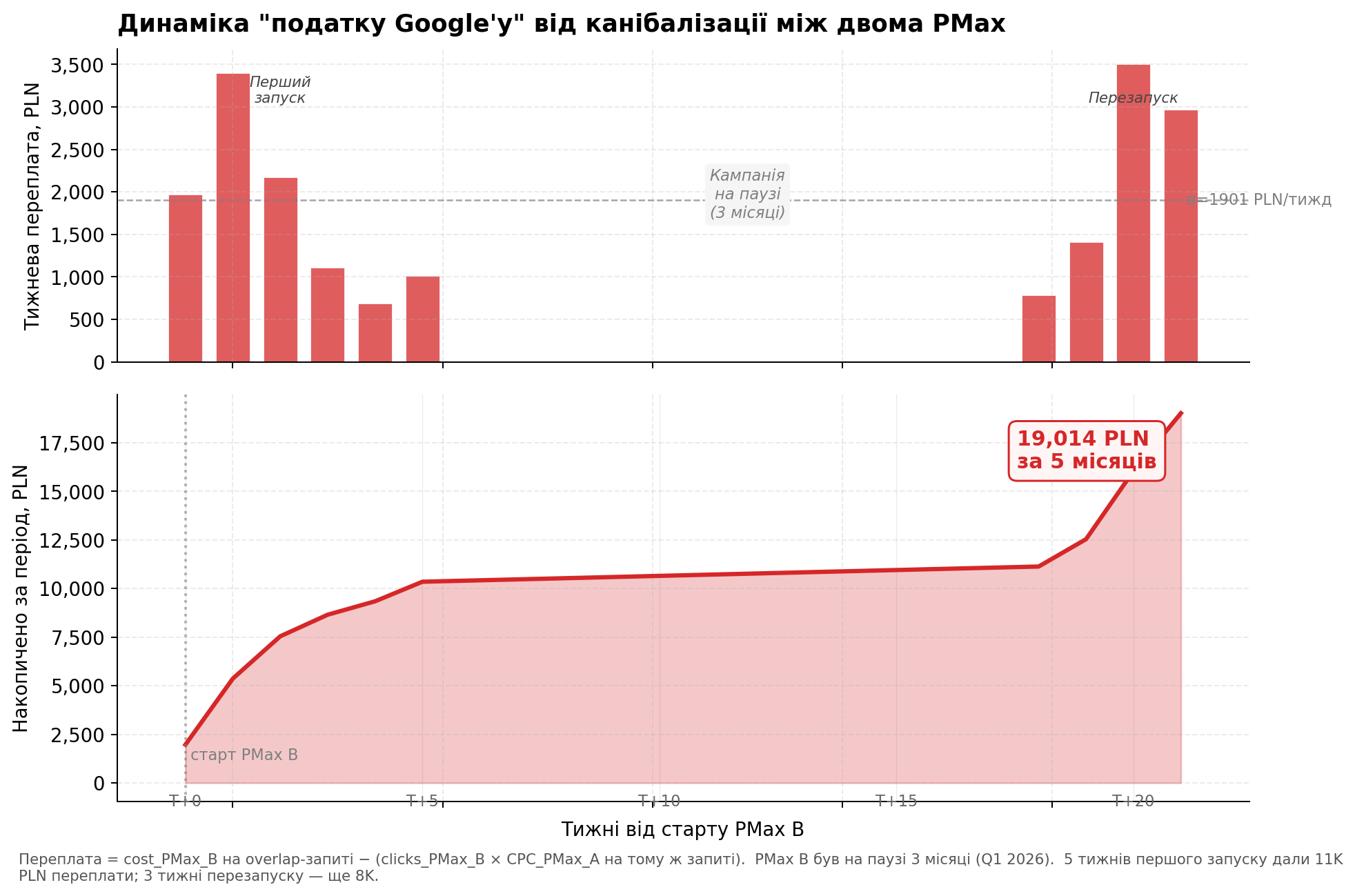
Графік 5. Тижнева переплата (зверху) і накопичена сума (знизу). PMax B був на паузі ~3 місяці посередині періоду — тому накопичена крива має плато.
Сумарна переплата за 5 місяців post-period = 19,014 PLN. Це чисті гроші передані Google через те що дві кампанії того ж акаунту піднімали ставку одна одній.
Цікавий патерн на графіку: переплата йшла лише в перші 5 тижнів запуску, потім стихла, потім спалахнула знову після перезапуску PMax B у квітні. Між ними — 3 місяці паузи коли кампанія B не була активна. Це підтверджує що ефект не “артефакт даних” — він прямо корелює з тим коли друга кампанія працює.
Проєкція на рік: ~45,000 PLN надлишкових витрат. На один акаунт. На одну пару кампаній. На цьому ж акаунті є інші пари з overlap, які я не аналізувала глибоко — реальна цифра по всьому акаунту скоріш за все вища.
Як це працює технічно?
Залишилось пояснити механіку. Чому дві PMax-кампанії одного акаунту взагалі конкурують між собою на аукціоні? Хіба Google не повинен їх “розводити”?
Відповідь — і так і ні. Google розводить покази, але не CPC. Вибірковість видно у самих числах: на overlap-запитах PMax A забирає 95% показів і конверсій, PMax B — 5%. Тобто система не пропускає обидві кампанії в той самий показ паралельно — лише одна з’являється на конкретному імпресіоні.
Але CPC цей розподіл не компенсує. Аукціон Google працює так що ставка кампанії залежить від конкуренції і її tROAS. Коли PMax B виходить на високооб’ємний запит з агресивною ставкою (Google прагне витратити її бюджет на найкращі позиції), вона змушує PMax A теж піднімати ставку — інакше PMax A перестане з’являтись. У результаті обидві платять більше, ніж заплатили б якби не конкурували.
Цікаво подивитись на топ-15 запитів які приносять найбільшу абсолютну переплату:
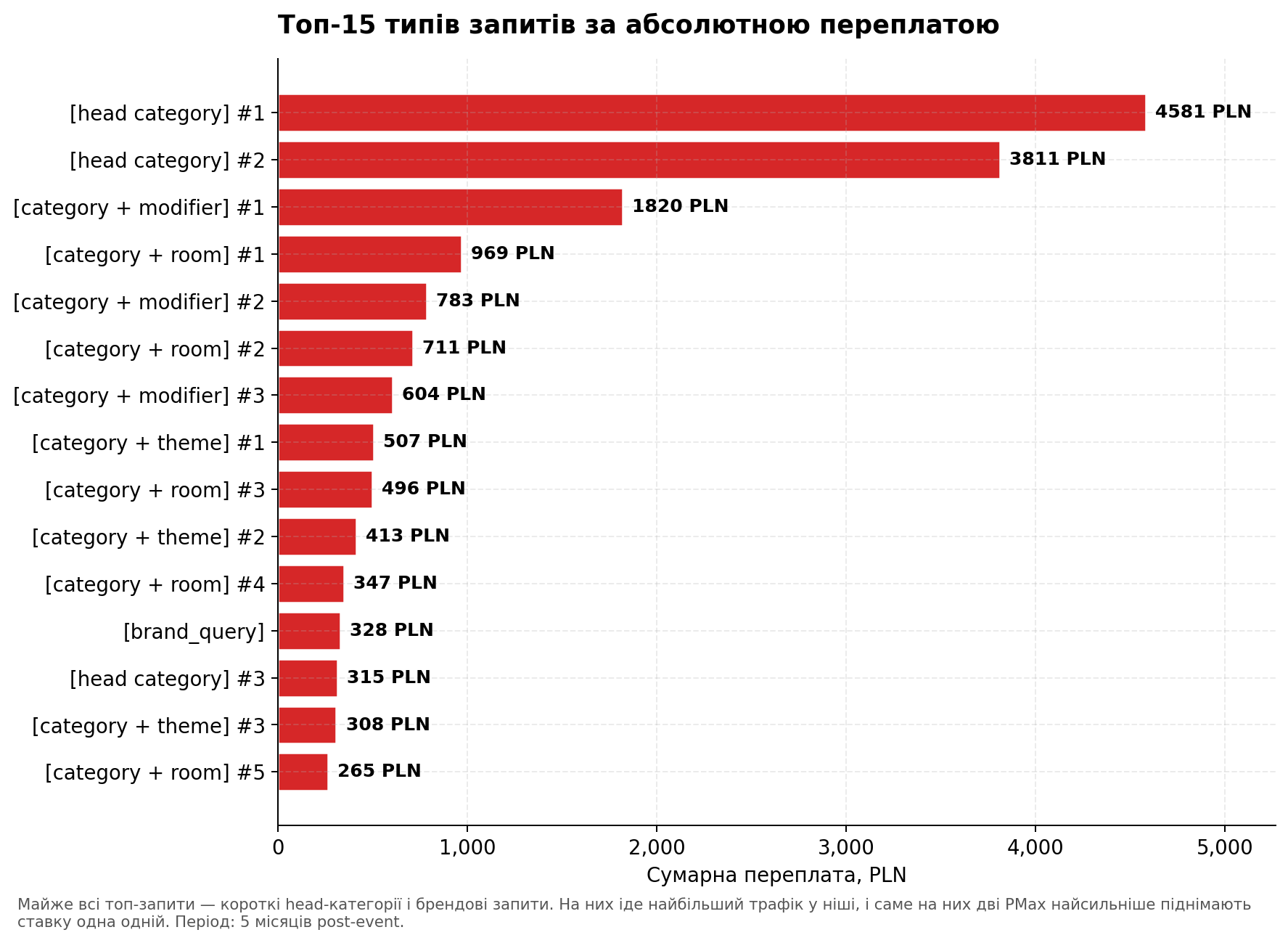
Графік 6. Топ-15 типів пошукових запитів за переплатою. Майже всі — короткі head-категорії і брендові запити.
Майже всі топ-запити — короткі узагальнені head-категорії і бренд. На них іде найбільший трафік у ніші, і саме на них алгоритм найсильніше піднімає ставку. На long-tail запитах ефект слабший — там аукціонна щільність нижче, і інтерференція менш помітна.
Це збігається з логікою Висновку 1 — bid escalation росте з об’ємом запиту. На рідкісних long-tail запитах PMax B переплачує помірно (+30%). На дорогих head-запитах — у 2 рази. У підсумку основна сума переплати концентрується саме на тих 10-15 запитах які приносять найбільший обсяг трафіку.
Що говорить документація Google?
У офіційній довідці Google прямо вказано що PMax враховує сигнали з усього акаунту. У офіційному анонсі Performance Max з 2021 року: “Performance Max uses your campaign goals, audience signals, and assets across the account to find new conversion opportunities.” Тобто алгоритм навмисно дивиться на широку картину акаунту, не ізолює кожну кампанію в свою воронку.
На практиці це означає: дві PMax-кампанії одного акаунту, навіть з різними фідами, навіть з різними audience signals — це не “дві незалежні системи”. Це дві гілки однієї матриці яка всередині конкурує за бюджет, конверсії і покази. Дублювання item_id через `df_` префікс не обходить цю архітектуру — лише робить інтерференцію помітнішою.
Висновки
Дослідження дало три основні висновки і одне узагальнення:
Канібалізація на аукціоні є і виміряна
На пошукових запитах де обидві PMax активні слабша кампанія платить на 30-100% дорожче за клік, залежно від інтенсивності аукціону. На топ-запитах — у 2 рази дорожче. 88.9% запитів які ловить друга кампанія одночасно ловить і перша.
“Сегментація аудиторій” — міф
AOV однаковий у двох кампаніях якщо рахувати на репрезентативній вибірці. Загальне середнє може здаватись різним лише через хвостову нерівномірність розподілу — артефакт малих чисел, не реальна сегментація. Виправдання “одна ловить дешевих, інша дорогих” не підтверджується.
Реальний CPA завищений на 21%
Через атрибуційний шлях у 3.5 взаємодії на конверсію, дві кампанії розподіляють між собою кліки одного й того ж покупця. У звітах окремих кампаній CPA виглядає нормальним (340 і 334 PLN). Реальний CPA на покупця = 235 PLN. Контрфакт без дублювання = 194 PLN. Завищення на 21% (+41 PLN на конверсію).
Дві PMax-кампанії на той самий товарний фід — це не “хеджування” і не “AB-тест”. Це структурний податок Google. На пошуковому запиті де обидві активні, CPC слабшої росте на 30-100%. Жодної реальної сегментації аудиторій між кампаніями немає. Сумарний CPA акаунту завищений на 20%+. У звітах окремих кампаній це невидимо. Тільки сумарна економіка акаунту по ключових SKU виявляє патерн.
Обмеження дослідження
Чесно про слабкі сторони:
- Одна пара кампаній, одна ніша. Висновки можуть відрізнятись для інших ніш чи інших структур акаунту. Реплікація на 5-10 акаунтах різних ніш дала б більш робастну картину.
- Контрфакт — припущення. Я припускаю що без PMax B всі конверсії все одно прийшли б через PMax A. Це правдоподібно але не доведено. Чистий тест — A/B з вимкненням PMax B на 4 тижні.
- Конфаундери у change history. 89 критичних змін tROAS і бюджету за період порушують умову “all else equal”. Longitudinal-висновок з пари A на цьому акаунті частково скомпрометовано. Cross-sectional на парі B залишається валідним.
- Не аналізую другорядні пари. Топ-3 пари за overlap зосереджені навколо однієї великої кампанії (PMax A). Можливо у пар без її участі патерн інший. Це наступний крок дослідження.
Відкриті питання
Дослідження не дало відповіді на:
- Чи однаково сильна канібалізація на акаунтах з коротшим атрибуційним шляхом (1.5-2 взаємодії на конверсію). Гіпотеза — слабша, бо менше шансів на повторні кліки.
- Чи можна зменшити канібалізацію через жорсткі audience signals або негативні keywords (хоча у PMax немає прямих негативних keywords).
- Як веде себе друга PMax на акаунтах де перша має дуже малий бюджет — чи можливий зворотний ефект коли друга кампанія “тягне” за собою першу.
- Як виглядає аналогічний аналіз для Standard Shopping + PMax замість PMax + PMax.
Це матеріал для майбутніх частин серії досліджень PMax-алгоритму.
FAQ
-
Не завжди, але у переважній більшості випадків зараз — так. Виняток — кейси коли дві кампанії реально мають різну економічну логіку: різні країни, різні мови, різні етапи воронки (наприклад одна на нових клієнтів, друга на ремаркетинг). У таких випадках overlap природно низький, і канібалізації не виникає. У e-commerce кабінеті де обидві PMax таргетяться на ту саму ринкову нішу і той самий товарний фід — overlap буде близько 90%, як у цьому дослідженні, і дублювання шкодить.
-
Найпростіший спосіб — відкрити звіт “Товари → Статус у кожній кампанії” в Google Ads UI. Якщо побачите що той самий item_id “придатний у стількох кампаніях: 2, 3, 6” і це PMax-кампанії — у вас точно є overlap. Глибша перевірка — експортувати звіт по пошукових термінах за період коли обидві кампанії активні, і подивитись скільки запитів спільних. Якщо overlap >50% від меншої кампанії і вона показала помітний об’єм трафіку — канібалізація майже гарантована.
-
Документація Google не забороняє дублювання, але й не радить. У ній прямо вказано що PMax враховує сигнали з усього акаунту — тобто Google знає про architecture-наслідки, але не зобов’язаний попереджати про економічні. Що логічно: переплата за подвійну участь — це дохід Google, не його проблема. Алгоритм робить технічно те що від нього просять (показуватись на тому SKU у двох кампаніях), просто з вищою сумарною ціною за результат.
-
Якщо ціль — розділити кампанії на різні товарні групи без overlap, custom_label сегментація ефективна. Один SKU попадає тільки в одну кампанію за правилом — і канібалізації немає за визначенням. Якщо ціль — дублювати SKU у двох кампаніях через `df_` префікс притому, що custom_label не використовується для розділення — сегментація не допомагає, бо вона не активна. У дослідженні я не аналізувала акаунт з custom_label архітектурою — це окреме питання для майбутньої статті.
-
Так, сильніше. На акаунтах з малим бюджетом кампанії частіше упираються в ліміт — і коли так відбувається, аукціонна динаміка спотворюється: алгоритм агресивніше торгується, щоб встигнути витратити бюджет до кінця дня. Дві малобюджетні PMax на ті самі товари створюють сильніший bid escalation, ніж дві добре забюджетовані. Плюс на малих бюджетах кожна додаткова конверсія коштує дорожче через ефект learning phase — який починається наново при кожному перезапуску. У цьому дослідженні я працюю з акаунтом середнього розміру, тому 21% — це швидше нижня межа ефекту, не верхня.
-
Найкраще — показати клієнту цифри. Цей текст і написаний для того, щоб конкретний кейс можна було використати як аргумент. Якщо клієнт продовжує наполягати, варіант “м’якого” розв’язання — зробити кампанії максимально різними за всіма іншими параметрами: різні товарні групи через listing groups (мінімум overlap по SKU), різні цілі тендеру (одна на ROAS, інша на conversions), різні landing pages. Це не повністю усуває канібалізацію, але мінімізує її. Жорстке розв’язання — поставити A/B тест: вимкнути одну з кампаній на 2-3 тижні і виміряти чи погіршився сумарний CPA акаунту. Якщо ні — рішення приймає себе.