Estudio de la canibalización oculta en Google Ads con datos brutos de una cuenta de e-commerce: 16 meses de historial, 2.24 millones de filas de términos de búsqueda, cuatro hipótesis revisadas.
¿Por qué decidí hacer esta investigación? Veo cómo está cambiando el enfoque de la IA dentro de Google Ads. Cuando todavía funcionaba Smart Shopping, Performance Max era muy básico — en 2024, en PMax se podían probar distintas audiencias en señales con los mismos productos, y las campañas realmente se movían en direcciones diferentes. El algoritmo se orientaba principalmente a la audiencia — y funcionaba.
A partir de 2025, vi que el enfoque empezó a cambiar. Para finales de 2025, el algoritmo de PMax funciona de manera completamente diferente. Las señales de audiencia tienen cada vez menos peso; el algoritmo se fija cada vez más en las señales de toda la cuenta y decide de forma independiente hacia dónde va el tráfico. El viejo enfoque de “lancemos dos PMax con diferentes señales de audiencia para capturar audiencias distintas” dejó de funcionar — pero algunos anunciantes siguen probando audiencias como si aún estuviéramos en 2024.
Y cuando los clientes vienen a mí para una auditoría, el error típico que veo es: el mismo producto está en dos campañas de PMax. El enfoque se mantuvo desde la época en que tenía sentido. Ahora — ya no. Pero convencer a un anunciante con argumentos abstractos es difícil. Por eso esta investigación se basa en números, en datos brutos de una cuenta, mostrando por qué esa estructura ahora es perjudicial.
En una cuenta que acepté recientemente para auditoría, noté un patrón familiar: el mismo identificador de producto aparecía en dos campañas de PMax diferentes simultáneamente. Junto al ID nativo SKU_25570 en el informe aparecía df_SKU_25570 — el mismo producto, pero con un ID modificado debido a la duplicación del feed en Merchant Center. Dos campañas de Performance Max veían el mismo SKU, ambas estaban mostrando anuncios para él.
Este patrón es común en cuentas de e-commerce. Los account managers crean deliberadamente un “duplicado del feed” con el prefijo df_ precisamente para sortear la limitación técnica de “un SKU = una campaña” y lanzar un segundo PMax sobre el mismo producto. En la industria, existen tres justificaciones típicas para hacer esto:
- Segmentación de audiencias — supuestamente, dos campañas “capturan” diferentes segmentos de clientes: una atrapa a quienes buscan más barato, la otra a clientes de mayor valor.
- Cobertura de riesgos — si el algoritmo de una campaña “se rompe” o pierde su aprendizaje, la segunda servirá como respaldo.
- Prueba A/B oculta — comparar diferentes tROAS, diferentes señales de audiencia, diferentes conjuntos de assets en los mismos productos.
Cada una de estas justificaciones suena racional. Pero se basan en suposiciones sobre cómo se comporta realmente el algoritmo de Performance Max cuando se encuentra con dos campañas de la misma cuenta compitiendo por un mismo SKU. Quería verificarlo con datos reales.
La pregunta de investigación era simple: ¿dos PMax para un mismo producto se canibalizan entre sí en la subasta? Si es así — ¿cómo exactamente y cuánto cuesta? Si no — ¿quizás este patrón es realmente útil para el negocio?
Spoiler: la respuesta resultó ser más compleja que cualquiera de los tres escenarios que esperaba.
Datos y metodología
El estudio se realizó en una cuenta de e-commerce de la categoría de artículos para el hogar. Período de datos — 16 meses: 30 de diciembre de 2024 → 20 de abril de 2026. No gestionaré esta cuenta públicamente, por lo que en lugar de nombres reales de campañas, uso designaciones neutrales: PMax A — campaña antigua, funcionó todo el período; PMax B — campaña nueva, comenzó a mitad del período.
Datos
La exportación de Google Ads se realizó en cinco exportaciones separadas debido al límite de filas de Google Ads. Combiné y limpié:
- Informe de productos en Shopping — 1.65 millones de filas. Segmentación: campaña × semana × ID de producto. 22 campañas de PMax, de las cuales se usaron tres para el análisis. ~30,000 SKU únicos.
- Informe de términos de búsqueda — 2.24 millones de filas. El mismo período y las mismas tres campañas. 245,000 términos de búsqueda únicos.
- Historial de cambios de campañas — 986 registros de cambios de tROAS, presupuestos y estados durante 16 meses. Críticamente importante para controlar factores de confusión.
Limpié los números del formato europeo (coma decimal, espacios en números, comillas), normalicé el item_id (eliminé el prefijo df_ de los duplicados del feed), filtré solo aquellos SKU que pertenecen al dominio analizado (89.8% de todas las filas — el resto se descartó como productos de otros sitios de la cuenta).
Trampas metodológicas que abordé
Este es mi cuarto estudio del algoritmo PMax con datos brutos. En los tres anteriores, caí en cuatro trampas que arruinaron las conclusiones iniciales. Aquí las abordé conscientemente incluso antes de comenzar el análisis:
Trampa 1 — formato de item_id
Los ID de productos en dos feeds pueden tener prefijos diferentes. En mi caso, 4,642 de 9,631 SKU tenían el prefijo df_ (duplicado del feed). Sin normalización, el emparejamiento de SKU compartidos daría un 12% en lugar del 50% real. Verificación: para todos los 2,375 SKU que tenían ambas versiones, el ID de Merchant Center en df_X y X coincide. Es decir, df_X y X son el mismo producto del mismo MC, solo que con un ID modificado.
Trampa 2 — sesgo de selección
Si agrupas los SKU por su actividad después de un evento inicial — Google mismo selecciona los SKU principales para la segunda campaña, y el “efecto de campaña” resulta ser un sesgo de selección. Yo fijo los grupos de SKU según la actividad del período previo (antes del lanzamiento de la segunda campaña) y luego observo cómo se comporta cada grupo después.
Trampa 3 — factores de confusión del historial de cambios
Un factor de confusión es un factor que cambia en paralelo con lo que estamos estudiando y, debido a esto, puede crear la ilusión de una relación causa-efecto. Un ejemplo simple: si quiero medir el efecto del lanzamiento de un segundo PMax en el CPC, y precisamente en esa misma semana aumenté el tROAS en la primera campaña — el aumento del CPC podría atribuirse a cualquiera de estos dos cambios. Eso es un factor de confusión.
Cualquier cambio en tROAS, presupuesto o filtro de productos durante el período de análisis crea un factor de confusión. Extraje el historial completo de cambios de las tres campañas. El resultado mostró 89 cambios críticos (tROAS, presupuesto, estado) en 17 meses en un par. En una ventana de ±6 semanas alrededor del evento inicial — 40 cambios. Esto no es un “experimento natural limpio”, y hay que reconocerlo honestamente.
Trampa 4 — ciclo de vida de los productos
En un estudio anterior, los 50 SKU principales resultaron ser una tendencia de género específica que se estaba enfriando naturalmente. La “caída de PMax” parecía un efecto algorítmico, pero era un ciclo de demanda. Antes de sacar conclusiones, analicé los 20 SKU compartidos principales por conversiones: son un catálogo permanente de decoración de paredes con demanda constante, no artículos estacionales.
Diseño del estudio
Me centré en dos pares de campañas con el mayor gasto en SKU compartidos:
- Par A (longitudinal): PMax A (antigua, funcionando >12 meses) y PMax B (nueva, comenzó a mitad del período). 21 semanas de historial compartido. Evento de referencia = semana de lanzamiento de PMax B. Permite comparar “antes” y “después” de la aparición de la segunda campaña.
- Par B (transversal): PMax A y otra campaña antigua que funcionó todo el período. 68 semanas de historial compartido. Aquí no hay evento de referencia — comparo SKU compartidos vs individuales dentro del período. Sirve como validación de las conclusiones del Par A con datos independientes.
Un tercer candidato para comparación longitudinal resultó no ser adecuado: la campaña operaba con un formato de ID diferente (sin el sufijo de dominio característico), por lo que los SKU no coincidían con los nuestros. Descartado.
Una de las decisiones metodológicas clave — comparo solo las mismas unidades. No “SKU compartido vs SKU individual” (son grupos de productos diferentes con características diferentes), sino “el mismo SKU en dos campañas en la misma semana”. Esto aborda una tercera capa importante de sesgo de selección.
Insight 1: Dos PMax se pujan entre sí en las mismas consultas
Lo primero que quería averiguar — ¿las campañas capturan las mismas consultas de búsqueda? ¿Quizás Google las separa internamente en diferentes subastas (una en consultas de categoría, la otra en consultas de marca, por ejemplo)? Si es así — no hay canibalización por definición.
Calculé la superposición de términos de búsqueda entre PMax A y PMax B en el período posterior — después de que la segunda campaña se lanzara. Resultado:
- Términos de búsqueda únicos en PMax A: 88,027;
- Términos de búsqueda únicos en PMax B: 35,496;
- Superposición: 31,552 — es el 88.9% de la campaña más pequeña.
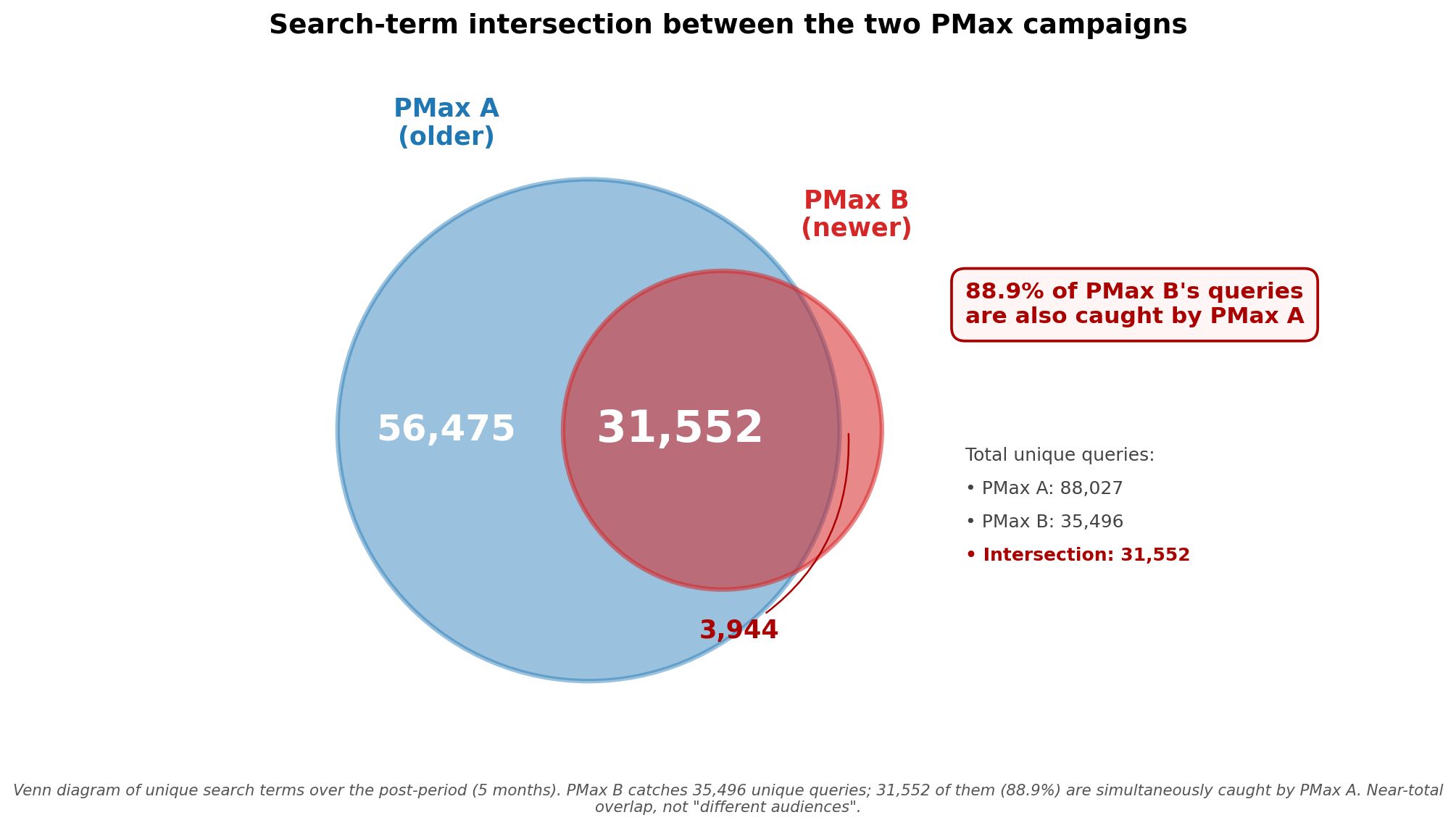
Gráfico 1. Diagrama de Venn de la superposición de consultas de búsqueda. Casi todas las consultas que captura PMax B también las captura PMax A simultáneamente.
El 88.9% de las consultas que captura PMax B también las captura PMax A simultáneamente. Esto no son “audiencias diferentes” — es una superposición casi completa. La hipótesis de que Google separa las campañas a nivel de consultas queda descartada.
A continuación — la prueba principal. En las consultas donde ambas campañas recibieron un clic en la misma semana, comparé el CPC. Si el algoritmo de Performance Max separa eficazmente las campañas a nivel de subasta — el CPC en ambas campañas debería ser aproximadamente igual. Si compiten entre sí — la puja de la campaña más débil será más alta.
¿Qué muestra el CPC en las consultas superpuestas?
4,386 pares “consulta × semana” donde ambas campañas recibieron un clic. CPC ponderado (ponderado por clics):
- PMax A: 1.73 PLN;
- PMax B: 3.01 PLN;
- Diferencia: PMax B es un 74% más caro.
En el 58% de las observaciones, PMax B es más caro que PMax A por el mismo clic. La distribución es desigual — en la cola (P90), PMax B paga 3.6 veces más; en P95 — 6 veces más. Esto no es “ruido”. Es un patrón claro de escalada de pujas: cuando dos postores de la misma cuenta entran en la misma subasta, la puja sube.
Aún más interesante — cómo depende este patrón del volumen de consultas. Dividí las consultas superpuestas en 5 segmentos según la cantidad de clics que recibió PMax B:
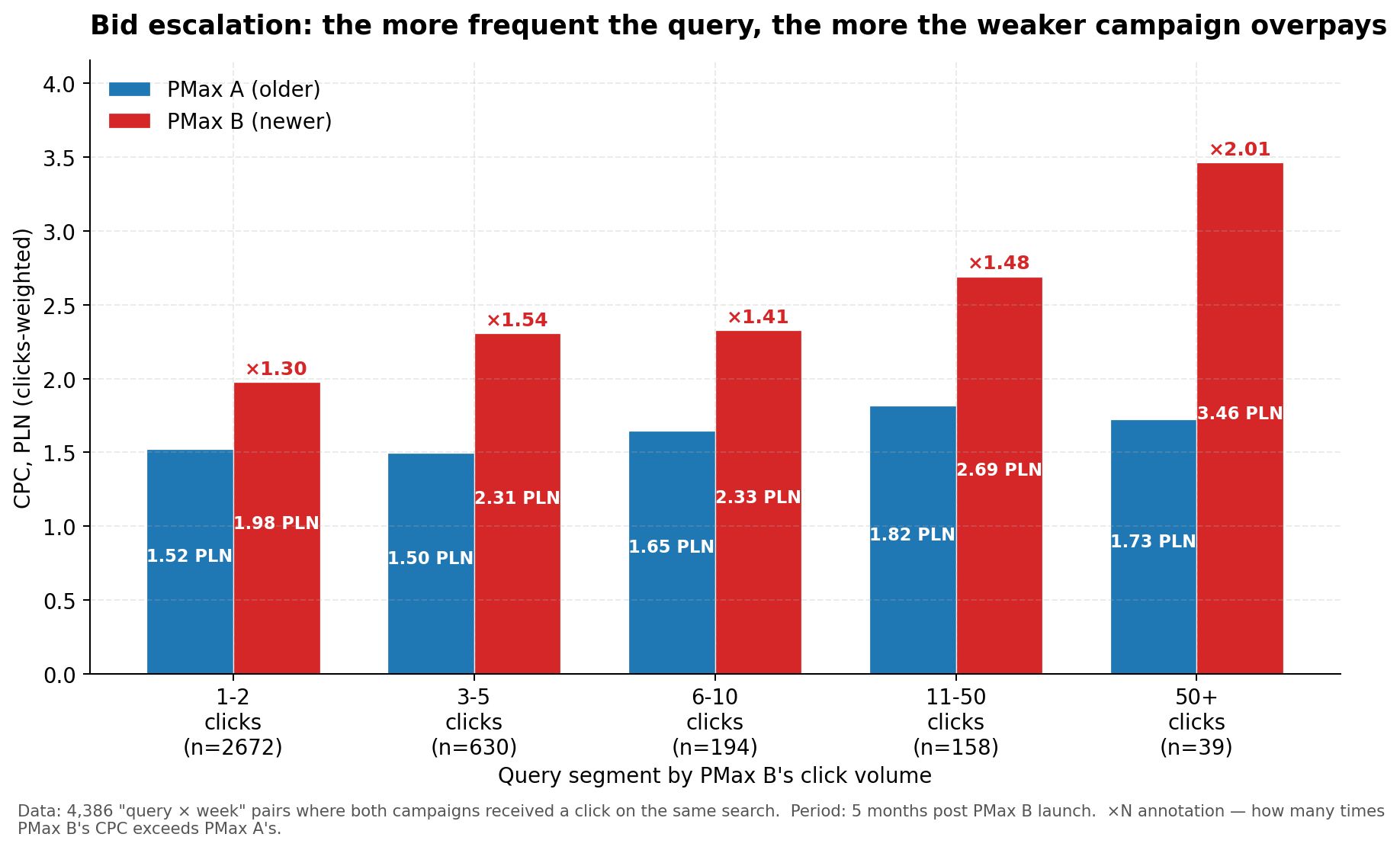
Gráfico 2. Escalada de pujas por volumen de consultas. En consultas raras (1-2 clics), PMax B paga +30%; en consultas principales (50+) — 2 veces más caro.
Cuanto más intensa es la subasta, mayor es el impuesto por participación doble. En consultas raras (1-2 clics por semana), PMax B paga moderadamente más — +30%. En las medianas — +40-55%. En las consultas principales con mucho tráfico (50+ clics por consulta por semana), PMax B ya paga 2 veces más que PMax A.
Lo que quiero decir con “impuesto por participación doble”. Cuando dos campañas de la misma cuenta están en una misma subasta de Google, el algoritmo debe elegir entre ellas — y lo hace aumentando la puja. Como resultado, ambas campañas pagan más de lo que habría pagado un solo participante. Este recargo es el impuesto: dinero que la cuenta entrega a Google únicamente por el hecho de tener dos campañas sobre el mismo producto en el sistema, en lugar de una.
Esto es economía clásica de subastas: cuando una de las partes en una subasta tiene una puja agresiva, la otra se ve obligada a aumentar la suya para no desaparecer de las impresiones. En condiciones normales, este es un mecanismo de fijación de precios entre anunciantes independientes. Aquí, es un mecanismo de fijación de precios entre dos campañas de la misma empresa, que no tienen ninguna razón para competir entre sí — excepto que existen en paralelo.
Conclusión 1: cuanto más frecuente es la consulta de búsqueda, más fuerte es la canibalización. En las consultas principales, el CPC de la campaña más débil llega a 2x. Esto no es “Google separando campañas en diferentes consultas” — es Google enviando ambas a la misma subasta y cobrando una puja más alta.
¿Por qué esto coincide con lo que ven los profesionales?
Desde mi práctica: el comportamiento típico de PMax — si un producto fuerte está en dos campañas de PMax en una cuenta, una de ellas siempre es más cara. Lo veo constantemente. La escalada de pujas es un fenómeno que los profesionales de PPC han visto en sus propias cuentas durante años. Simplemente ahora se ha medido.
El segundo detalle importante — PMax no aísla las campañas a nivel de términos de búsqueda. En la documentación de Google se indica directamente: el algoritmo considera las señales de toda la cuenta cuando decide qué consulta asignar a qué entidad. Es decir, dos PMax no son “dos embudos” con sus propios embudos de consultas, sino dos hebras de la misma matriz. Y en los lugares donde estas hebras se cruzan — el algoritmo eleva la puja al nivel que ambas están dispuestas a pagar.
Insight 2: El mito de la segmentación de audiencias
La justificación más común para tener dos PMax es “una captura clientes más baratos, la otra captura clientes más caros — las audiencias están divididas”. Suena convincente: si PMax B captura clientes con un ticket promedio más alto, incluso el sobrepago en CPC está justificado — el valor es mayor.
En mis primeras iteraciones de análisis, estuve cerca de confirmar esta tesis. En PMax B, en consultas superpuestas, el AOV (ticket promedio por conversión) resultó ser de 1,150 PLN frente a 707 PLN en PMax A. Casi 1.6 veces más alto. Incluso pensé por un momento que había encontrado un efecto positivo de la duplicación — “PMax B captura clientes más caros”.
Pero profundicé y encontré un matiz. El AOV promedio general ocultaba la distribución por volumen de consultas. Si se calcula por separado por segmento — la imagen podría ser completamente diferente.
Dividí las consultas superpuestas en grupos por volumen y observé el AOV en cada uno:
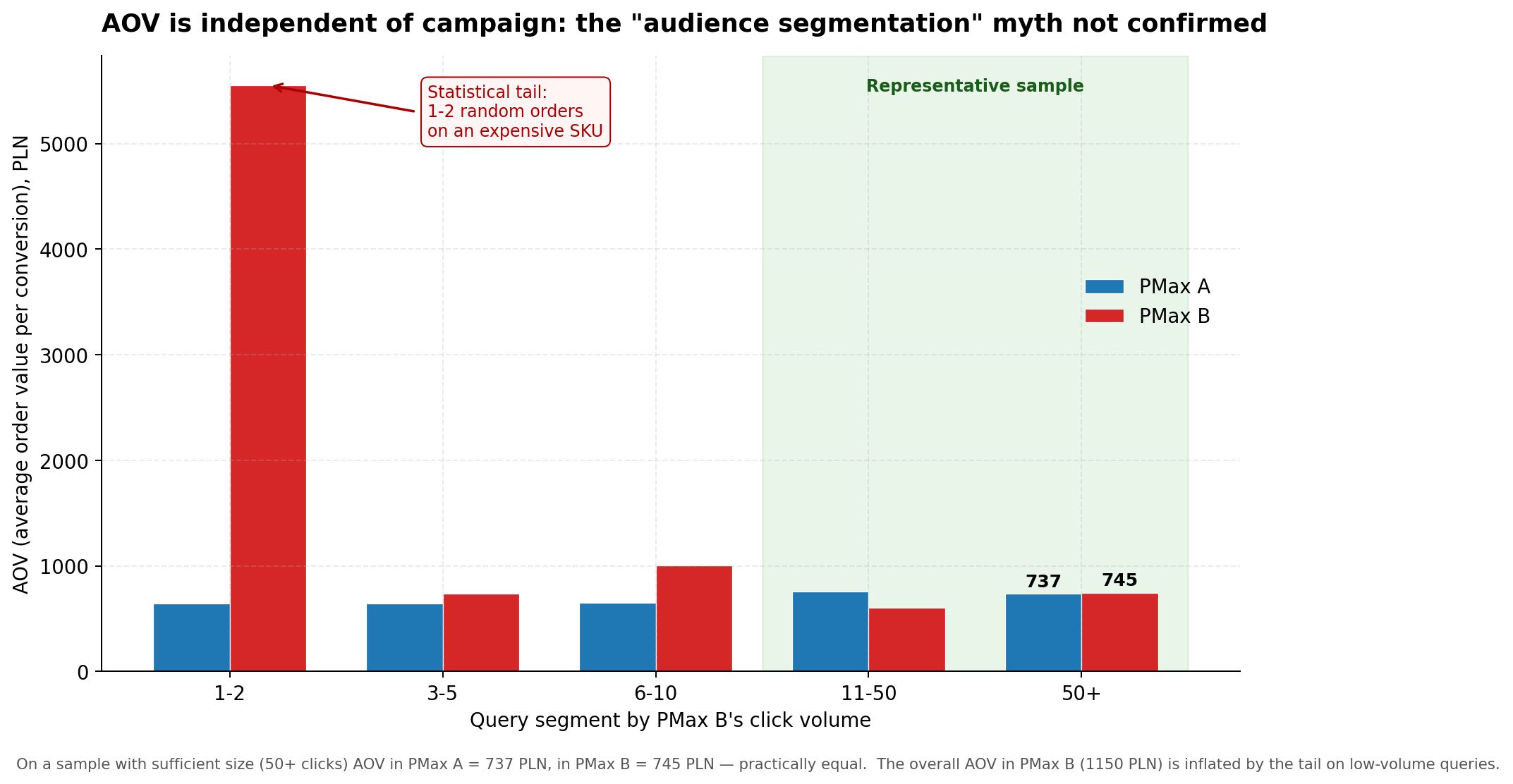
Gráfico 3. AOV por segmento de consultas. En una muestra representativa (50+ clics), el AOV en ambas campañas es prácticamente igual.
La imagen cambió por completo. En el grupo con tamaño muestral suficiente (50+ clics — el segmento más representativo), el AOV en PMax A = 737 PLN, en PMax B = 745 PLN. Prácticamente iguales.
El AOV promedio general de 1,150 PLN en PMax B resultó ser completamente un resultado de la cola en el grupo de 1-2 clics. Una o dos transacciones aleatorias en un SKU caro (ticket promedio ~5,500 PLN) inflaron el promedio del grupo. Si se descarta esa cola — no existe una “segmentación de audiencias por ticket” real entre las dos campañas de PMax.
Conclusión 2: el mito de la “segmentación por clientes caros y baratos” no se confirma. El AOV converge al promedio del nicho independientemente de cuál de las dos campañas de PMax haya capturado al cliente.
Este es un punto metodológicamente importante. En estadística, existe un efecto conocido: en una muestra pequeña, el promedio siempre es inestable. Un pedido grande de 5,000 PLN convierte un grupo de 10 clics en un “segmento de AOV alto”. Si un gerente observa la cifra agregada de PMax B — verá una ventaja imaginaria. Si observa la distribución por segmentos — verá que es un artefacto.
Este es el problema fundamental de cómo los profesionales de PPC a menudo evalúan las campañas: “AOV promedio en la campaña X”. Cuando una campaña tiene una distribución desigual del volumen entre las consultas (y en PMax esto es casi siempre así — 80/20), el promedio de la campaña no es representativo. Está ponderado precisamente por la cola.
¿Qué significa esto para la teoría de “audiencias diferentes”?
Si el AOV es el mismo, se derivan dos conclusiones lógicas:
- Performance Max no “segmenta” a los clientes por poder adquisitivo. El algoritmo, dentro de la misma consulta de búsqueda (“consulta de categoría”), dirige el tráfico a diferentes campañas, pero no por “tipo de cliente” — sino por otras señales (señales de audiencia en la campaña, creativos en grupos de assets, página de destino). El grupo real de audiencias que ve cada campaña es el mismo.
- Esto significa que no existe una “lógica de producto” real de segmentación en dos campañas de PMax — solo una artificial, mediante la duplicación del feed. Como resultado, dos campañas compiten por el mismo grupo de clientes con los mismos tickets promedio — solo que con diferentes conjuntos de assets.
Este es el punto donde la teoría de la “duplicación útil” se desmorona. Si el AOV es el mismo, entonces todo lo que ocurre es la escalada de pujas de la Conclusión 1, que no aporta valor adicional — solo aumenta los costos de la cuenta.
Insight 3: El CPA real por cliente está inflado en un 21%
Aquí cometí el error metodológico más grave en las primeras iteraciones, y así es como tuve que corregirlo.
Inicialmente, calculé el CPA por separado en cada campaña en las consultas superpuestas:
- CPA en PMax A en superposición: 340 PLN;
- CPA en PMax B en superposición: 334 PLN.
“Casi idéntico”. Concluí que las dos campañas eran económicamente neutrales — el sobrepago en CPC de PMax B (+74%) se compensaba con un CR más alto (2x), y en última instancia, el costo de adquisición de clientes era el mismo. La duplicación parecía no tener costo.
Pero mirar el CPA de esta manera — como una métrica simple de una campaña individual — es incorrecto para nuestro caso. Estaba viendo el CPA como si el cliente hiciera clic una vez y comprara inmediatamente. Pero en realidad, en esta cuenta, la ruta de atribución es de 3.5 interacciones / 2.6 días hasta la compra. Es decir, en promedio, 3.5 clics por conversión. Y cuando una cuenta tiene dos campañas de PMax en las mismas consultas de búsqueda, estos 3.5 clics se distribuyen entre las dos campañas. Aquí hay que calcular no el CPA de una campaña individual, sino el CPA por cliente en total.
Imaginemos la ruta real de un cliente: ve un anuncio de “consulta de categoría + especificador” y hace clic (PMax A). Un día después, busca de nuevo “consulta de categoría + tipo de habitación” y hace clic (PMax B). Otro día después, busca la marca y vuelve a hacer clic (PMax A). Luego compra. ¿Quién “trajo” esta conversión? En la atribución basada en datos — ambos. Cada campaña registra una parte de la conversión. En los informes: PMax A pagó 5 PLN por esa conversión, PMax B pagó 6 PLN, cada una muestra un CPA adecuado.
Pero el costo real de la conversión = 11 PLN. Es la suma de lo que dos campañas pagaron para adquirir un solo cliente. Y este número no se ve en ningún informe de Google Ads.
¿Cómo calculé el CPA real?
En las consultas superpuestas durante 5 meses del período posterior:
Métrica | Valor |
Gasto total (PMax A + PMax B) | 116,233 PLN |
Conversiones totales (ambas campañas) | 494 |
CPA real por cliente | 235 PLN |
Valor total (ambas campañas) | 427,514 PLN |
ROAS total | 3.68 |
CPA real = 235 PLN. No 340 ni 334 como se ve en los informes. 235.
Ahora la comparación contrafáctica. ¿Qué habría pasado si solo PMax A estuviera capturando estas consultas? Las conversiones igual habrían ocurrido — el cliente busca una consulta de categoría en el mismo sitio, con el mismo catálogo de productos. Habría hecho clic en PMax A en lugar de PMax B en uno de los pasos del camino y habría llegado a la misma compra. Los costos habrían sido menores porque el CPC en PMax A en consultas superpuestas = 1.73 PLN, mientras que en PMax B = 3.01 PLN.
Cálculo:
- Clics totales en superposición: 51,428;
- CPC en PMax A en superposición: 1.87 PLN;
- Costo contrafáctico (todos los clics al CPC de PMax A): 95,996 PLN;
- Conversiones (asumiendo las mismas): 494;
- CPA contrafáctico: 194 PLN.
Diferencia entre el CPA real y el contrafáctico = 41 PLN por conversión. En porcentaje — 21% de inflación.
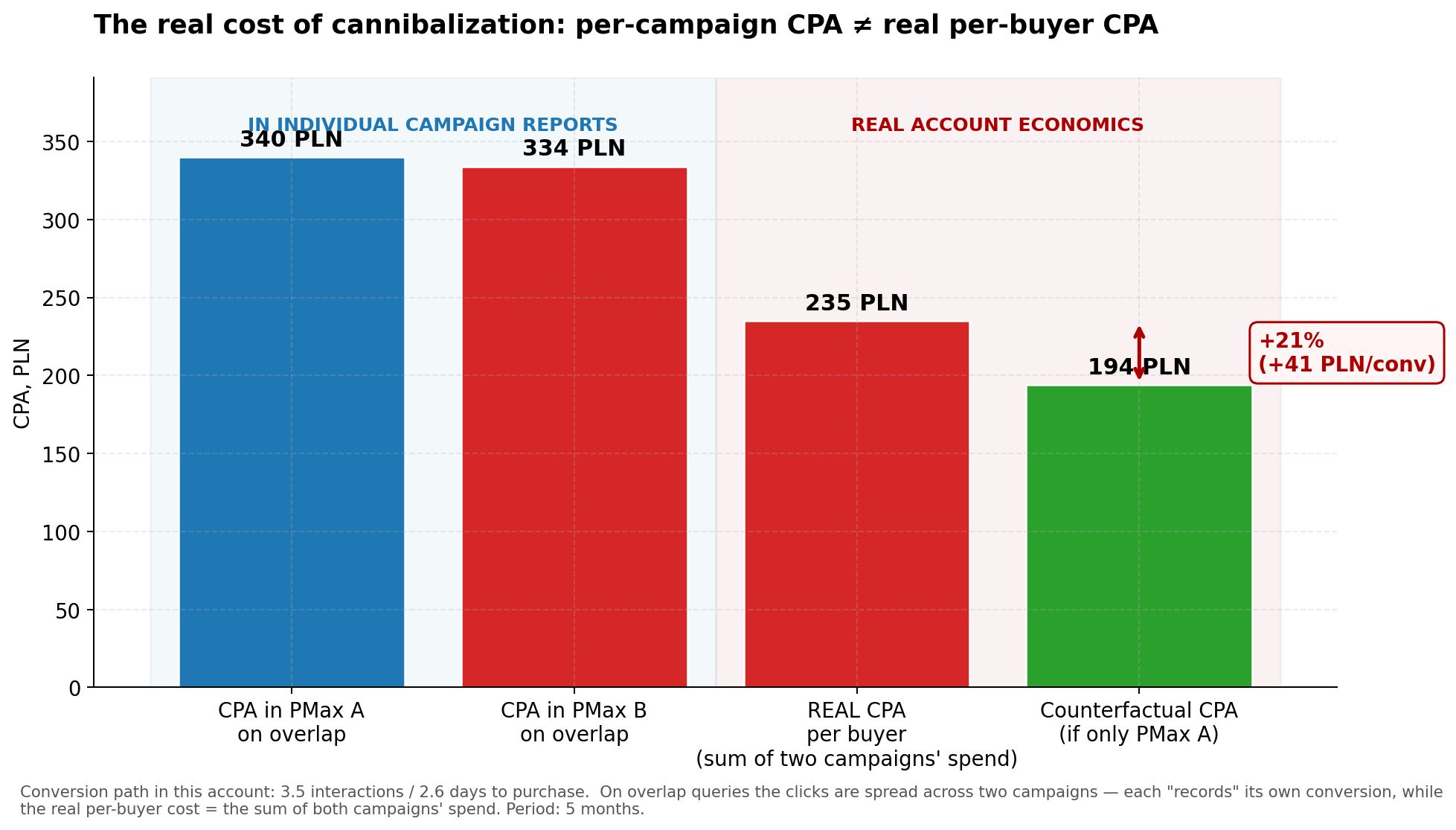
Gráfico 4. El CPA en campañas individuales (340 y 334 PLN) parece igual. El CPA real por cliente, considerando el gasto total de ambas campañas — 235 PLN. Contrafáctico sin duplicación — 194 PLN. Diferencia +21%.
Conclusión 3: la canibalización infla el CPA real por cliente en un 21%. En los informes de campañas individuales, esto no se ve — las métricas se ven normales. La inflación solo se nota al calcular la economía total de la cuenta por SKU clave.
¿Por qué es tan típico este error?
No soy la única que comete este error. Es la forma básica de ver el rendimiento de las campañas: abres un informe de campaña — ves el CPA. Si el CPA está dentro del KPI — la campaña está sana.
Pero esto solo funciona cuando las campañas son independientes. Si comparten la misma base de clientes — cada una muestra “su” parte de las mismas conversiones, y el CPA individual parece justo. La suma del gasto por cliente real — es invisible.
Cuanto más corta es la ruta de atribución, menos notable es el efecto. Si la cuenta tiene 1.2 interacciones por conversión — el sobrepago será de ~5%. Si es 3.5 — como en nuestro caso, 21%. Si es 5+ — podría ser del 35%+.
Con presupuestos pequeños y rutas de conversión complejas, el aumento de costo es aún mayor del 21%. Dos campañas de PMax en el mismo nicho incorporan un recargo oculto en el CPA, que el account manager no ve — porque en la campaña individual, las métricas se ven normales.
Sobrepago total en el tiempo
Calculé el sobrepago semanal en las consultas superpuestas. Fórmula: cost_PMax_B − (clicks_PMax_B × CPC_PMax_A en la misma consulta). Es decir, cuánto pagó PMax B de más en comparación con lo que PMax A habría pagado por los mismos clics.
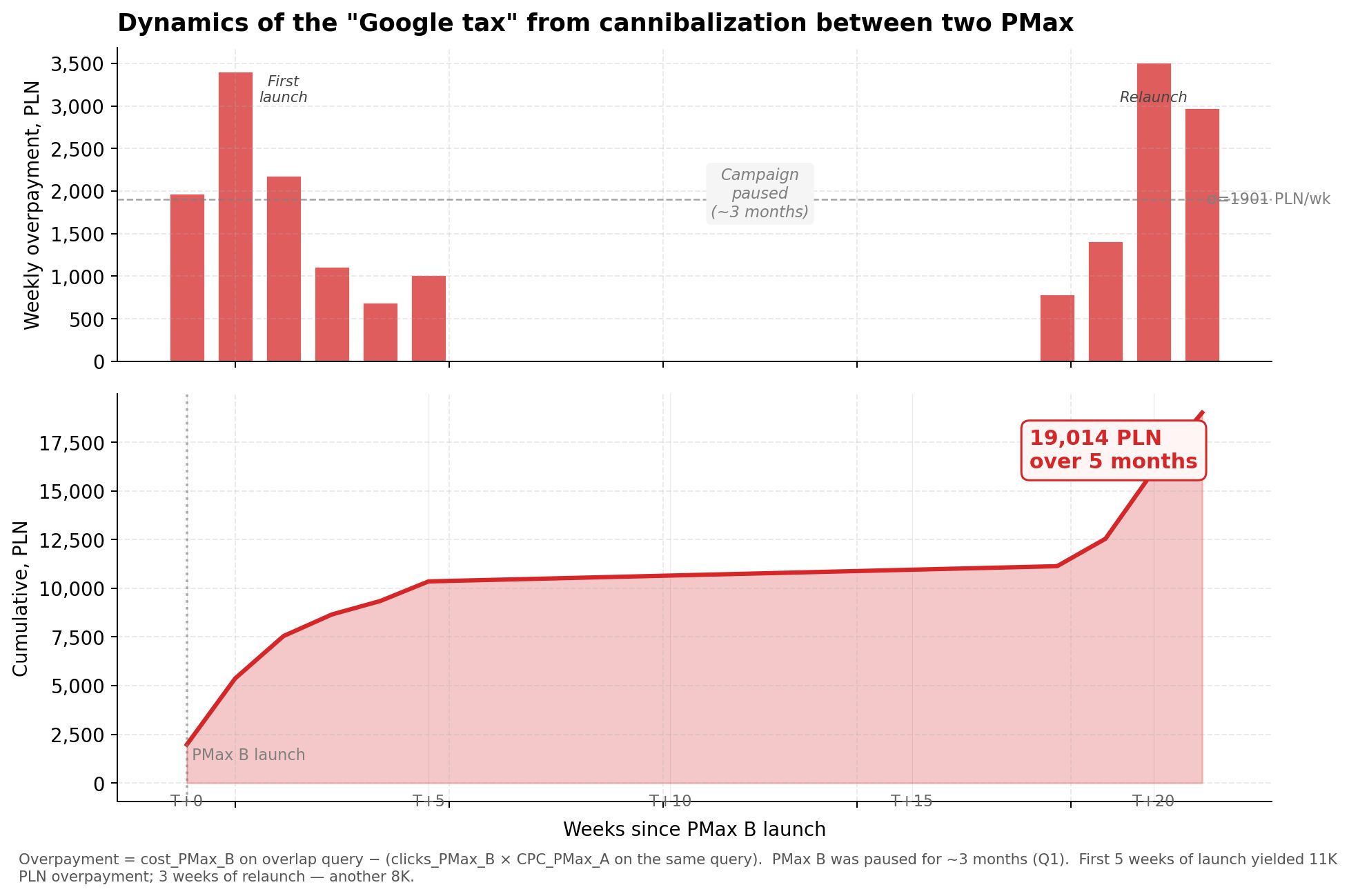
Gráfico 5. Sobrepago semanal (arriba) y suma acumulada (abajo). PMax B estuvo en pausa ~3 meses en medio del período — por eso la curva acumulada tiene una meseta.
Sobrepago total durante 5 meses del período posterior = 19,014 PLN. Este es dinero puro entregado a Google porque dos campañas de la misma cuenta se aumentaban las pujas entre sí.
Patrón interesante en el gráfico: el sobrepago ocurrió solo en las primeras 5 semanas del lanzamiento, luego se calmó, y luego volvió a aparecer después de reiniciar PMax B en abril. Entre medias — 3 meses de pausa cuando la campaña B no estaba activa. Esto confirma que el efecto no es un “artefacto de datos” — se correlaciona directamente con cuándo está funcionando la segunda campaña.
Proyección anual: ~45,000 PLN de gasto excesivo. En una cuenta. En un par de campañas. En esta misma cuenta hay otros pares con superposición, que no he analizado en profundidad — la cifra real en toda la cuenta probablemente sea mayor.
¿Cómo funciona técnicamente?
Queda explicar la mecánica. ¿Por qué dos campañas de PMax de la misma cuenta compiten entre sí en la subasta? ¿No debería Google “separarlas”?
La respuesta — sí y no. Google separa las impresiones, pero no el CPC. La selectividad se ve en los propios números: en las consultas superpuestas, PMax A se lleva el 95% de las impresiones y conversiones, PMax B — el 5%. Es decir, el sistema no deja que ambas campañas entren en la misma impresión en paralelo — solo una aparece en una impresión específica.
Pero el CPC no se compensa con esta distribución. La subasta de Google funciona de manera que la puja de una campaña depende de la competencia y de su tROAS. Cuando PMax B entra en una consulta de alto volumen con una puja agresiva (Google busca gastar su presupuesto en las mejores posiciones), obliga a PMax A a aumentar también su puja — de lo contrario, PMax A dejaría de aparecer. Como resultado, ambas pagan más de lo que habrían pagado si no compitieran.
Es interesante observar las 15 consultas principales que generan el mayor sobrepago absoluto:
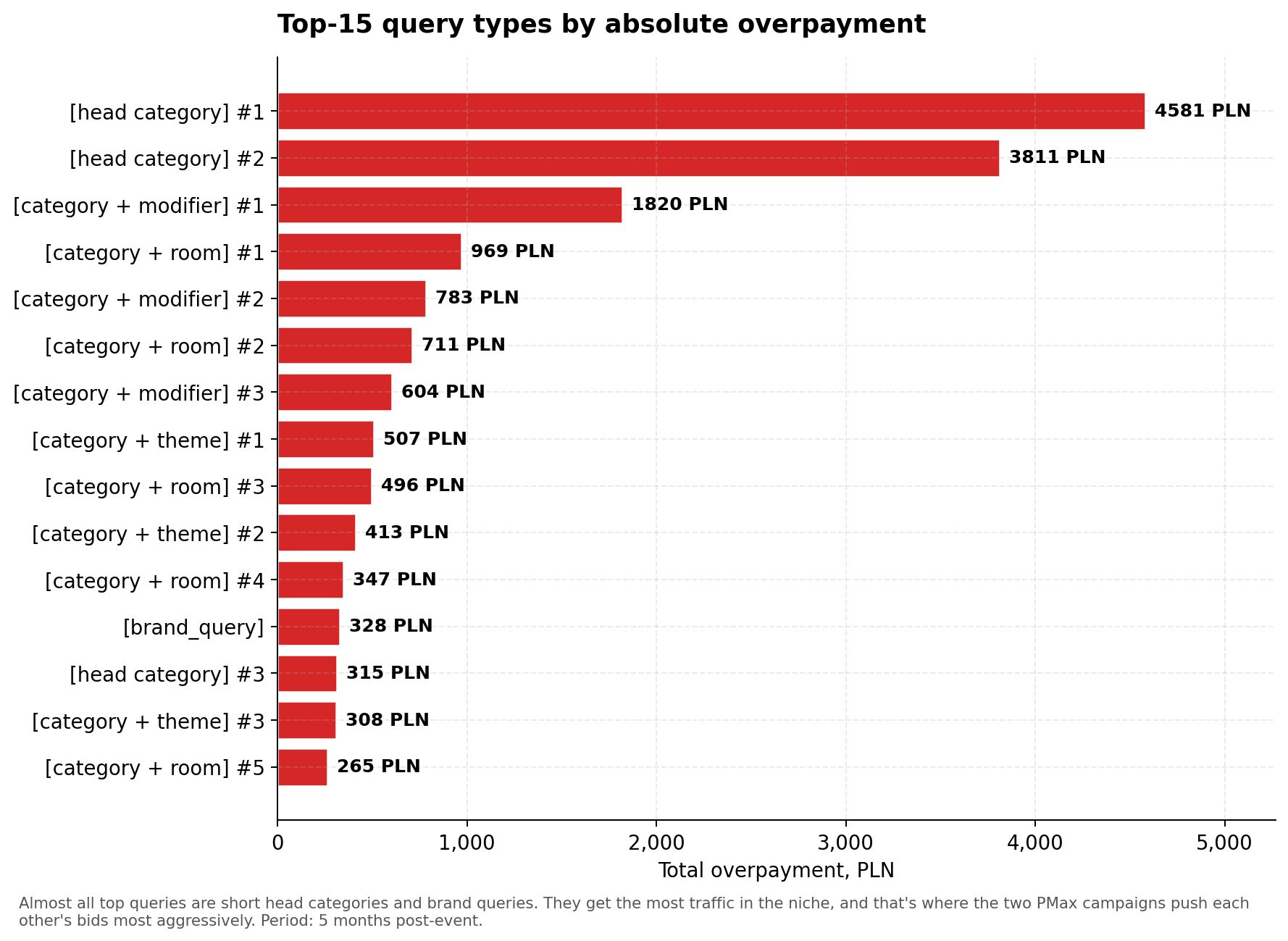
Gráfico 6. Top 15 tipos de consultas de búsqueda por sobrepago. Casi todas son categorías head cortas y consultas de marca.
Casi todas las consultas principales son categorías head generalizadas cortas y términos de marca. Estas generan la mayor cantidad de tráfico en el nicho, y es en estas donde el algoritmo aumenta más la puja. En las consultas de cola larga, el efecto es más débil — allí la densidad de subasta es menor y la interferencia es menos notable.
Esto coincide con la lógica de la Conclusión 1 — la escalada de pujas crece con el volumen de consultas. En consultas raras de cola larga, PMax B paga moderadamente más (+30%). En consultas head caras — 2 veces más. En última instancia, la mayor parte del sobrepago se concentra en las 10-15 consultas que generan el mayor volumen de tráfico.
¿Qué dice la documentación de Google?
En la documentación oficial de ayuda de Google se indica directamente que PMax considera las señales de toda la cuenta. En el anuncio oficial de Performance Max de 2021: “Performance Max utiliza los objetivos de tu campaña, las señales de audiencia y los assets de toda la cuenta para encontrar nuevas oportunidades de conversión.” Es decir, el algoritmo deliberadamente observa el panorama general de la cuenta, no aísla cada campaña en su propio embudo.
En la práctica, esto significa: dos campañas de PMax de la misma cuenta, incluso con diferentes feeds, incluso con diferentes señales de audiencia — no son “dos sistemas independientes”. Son dos ramas de la misma matriz que compite internamente por presupuesto, conversiones e impresiones. Duplicar el item_id mediante el prefijo df_ no evita esta arquitectura — solo hace que la interferencia sea más notable.
Conclusiones
El estudio produjo tres conclusiones principales y una generalización:
La canibalización en la subasta existe y es medible
En las consultas de búsqueda donde ambas campañas de PMax están activas, la campaña más débil paga entre un 30 y un 100% más por clic, dependiendo de la intensidad de la subasta. En las consultas principales — 2 veces más. El 88.9% de las consultas que captura la segunda campaña también las captura la primera.
La “segmentación de audiencias” es un mito
El AOV es el mismo en ambas campañas cuando se calcula en una muestra representativa. El promedio general puede parecer diferente solo por la desigualdad de la cola en la distribución — un artefacto de números pequeños, no una segmentación real. La justificación de que “una captura clientes baratos, la otra captura clientes caros” no se sostiene.
El CPA real está inflado en un 21%
Debido a una ruta de atribución de 3.5 interacciones por conversión, dos campañas se distribuyen entre sí los clics del mismo cliente. En los informes de campañas individuales, el CPA se ve normal (340 y 334 PLN). CPA real por cliente = 235 PLN. Contrafáctico sin duplicación = 194 PLN. Inflación del 21% (+41 PLN por conversión).
Dos campañas de PMax en el mismo feed de productos — esto no es “cobertura de riesgo” ni una “prueba A/B”. Es un impuesto estructural de Google. En una consulta de búsqueda donde ambas están activas, el CPC de la campaña más débil aumenta entre un 30 y un 100%. No existe una segmentación real de audiencias entre las campañas. El CPA total de la cuenta está inflado en un 20%+. Esto es invisible en los informes de campañas individuales. Solo la economía total de la cuenta por SKU clave revela el patrón.
Limitaciones del estudio
Honestamente sobre las debilidades:
- Un par de campañas, un nicho. Las conclusiones pueden diferir para otros nichos u otras estructuras de cuenta. La replicación en 5-10 cuentas de diferentes nichos proporcionaría una imagen más robusta.
- El contrafáctico es una suposición. Asumo que sin PMax B, todas las conversiones igual habrían llegado a través de PMax A. Esto es plausible pero no está probado. Una prueba limpia sería una prueba A/B desactivando PMax B durante 4 semanas.
- Factores de confusión en el historial de cambios. 89 cambios críticos de tROAS y presupuesto durante el período violan la condición de “todo lo demás constante”. La conclusión longitudinal del Par A en esta cuenta está parcialmente comprometida. La transversal del Par B sigue siendo válida.
- No analizo pares secundarios. Los 3 pares principales por superposición se concentran alrededor de una campaña grande (PMax A). Posiblemente, en pares sin su participación, el patrón sea diferente. Este es el siguiente paso de la investigación.
Preguntas abiertas
El estudio no respondió:
- Si la canibalización es igualmente fuerte en cuentas con rutas de atribución más cortas (1.5-2 interacciones por conversión). Hipótesis — más débil, porque hay menos oportunidades de clics repetidos.
- Si se puede reducir la canibalización mediante señales de audiencia estrictas o palabras clave negativas (aunque PMax no tiene palabras clave negativas directas).
- Cómo se comporta un segundo PMax en cuentas donde la primera tiene un presupuesto muy pequeño — si es posible un efecto inverso donde la segunda campaña “arrastra” a la primera.
- Cómo se ve un análisis similar para Standard Shopping + PMax en lugar de PMax + PMax.
Este es material para futuras partes de la serie de investigación del algoritmo PMax.
FAQ
-
No siempre, pero en la gran mayoría de los casos actuales — sí. La excepción son los casos donde dos campañas tienen genuinamente una lógica económica diferente: diferentes países, diferentes idiomas, diferentes etapas del embudo (por ejemplo, una para clientes nuevos, la otra para remarketing). En tales casos, la superposición es naturalmente baja y no se produce canibalización. En una cuenta de e-commerce donde ambas campañas de PMax se dirigen al mismo nicho de mercado y al mismo feed de productos — la superposición será de aproximadamente el 90%, como en este estudio, y la duplicación es perjudicial.
-
La forma más sencilla — abre el informe “Productos → Estado en cada campaña” en la interfaz de Google Ads. Si ves el mismo item_id “elegible en N campañas: 2, 3, 6” y son campañas de PMax — definitivamente tienes superposición. Una verificación más profunda — exporta el informe de términos de búsqueda del período en que ambas campañas están activas y observa cuántas consultas son compartidas. Si la superposición es >50% de la campaña más pequeña y ha mostrado un volumen de tráfico notable — la canibalización es casi segura.
-
La documentación de Google no prohíbe la duplicación, pero tampoco la recomienda. Indica directamente que PMax considera las señales de toda la cuenta — es decir, Google conoce las consecuencias arquitectónicas, pero no está obligado a advertir sobre las económicas. Lo cual es lógico: el sobrepago por participación doble es ingreso de Google, no su problema. El algoritmo hace técnicamente lo que se le pide (mostrarse en ese SKU en dos campañas), solo que a un precio total más alto por resultado.
-
Si el objetivo es dividir las campañas en diferentes grupos de productos sin superposición, la segmentación con custom_label es efectiva. Un SKU cae en solo una campaña por regla — y la canibalización está ausente por definición. Si el objetivo es duplicar SKU en dos campañas mediante el prefijo
df_mientras que custom_label no se usa para la separación — la segmentación no ayuda porque no está activa. En el estudio, no analicé una cuenta con arquitectura de custom_label — es una pregunta aparte para un futuro artículo. -
Sí, más fuertemente. En cuentas con presupuesto pequeño, las campañas alcanzan su límite presupuestario con más frecuencia — y cuando esto sucede, la dinámica de la subasta se distorsiona: el algoritmo puja de manera más agresiva para gastar el presupuesto antes de que termine el día. Dos PMax con presupuesto pequeño en los mismos productos crean una escalada de pujas más fuerte que dos bien presupuestadas. Además, en presupuestos pequeños, cada conversión adicional cuesta más debido al efecto de la fase de aprendizaje — que se reinicia con cada relanzamiento. En este estudio, trabajo con una cuenta de tamaño mediano, por lo que el 21% es más bien el límite inferior del efecto, no el superior.
-
Lo mejor — mostrarle al cliente los números. Este texto fue escrito precisamente para que un caso concreto pueda usarse como argumento. Si el cliente sigue insistiendo, una solución “suave” es hacer que las campañas sean lo más diferentes posible en todos los demás parámetros: diferentes grupos de productos mediante listing groups (mínima superposición de SKU), diferentes objetivos de puja (una en ROAS, la otra en conversiones), diferentes páginas de destino. Esto no elimina completamente la canibalización, pero la minimiza. La solución dura — realizar una prueba A/B: desactivar una de las campañas durante 2-3 semanas y medir si el CPA total de la cuenta empeoró. Si no — la decisión se toma sola.