Исследование скрытой каннибализации в Google Ads на сырых данных e-commerce аккаунта: 16 месяцев истории, 2.24 миллиона строк поисковых запросов, четыре рассмотренные гипотезы.
Почему я взялась за это исследование? Я вижу, как меняется подход ИИ внутри Google Ads. Пока еще работал Smart Shopping, Performance Max был совсем сырым — в 2024 году в PMax можно было хорошо тестировать разные аудитории в сигналах с теми же товарами, и кампании реально двигались в разные стороны. Алгоритм ориентировался в первую очередь на аудиторию — и это работало.
С 2025 года я увидела, что подход начал меняться. К концу 2025 года PMax-алгоритм работает совершенно по-другому. Аудиторные сигналы имеют все меньше веса, алгоритм все сильнее смотрит на сигналы со всего аккаунта и самостоятельно решает, куда идет трафик. Старый подход «запустим две PMax с разными audience signals, чтобы ловить разные аудитории» перестал работать — а часть рекламодателей продолжает тестировать аудитории так, будто на дворе 2024 год.
И когда клиенты приходят ко мне на аудит — типичная ошибка, которую я вижу: один и тот же товар находится в двух PMax-кампаниях. Подход сохранился с тех времен, когда он имел смысл. Сейчас — не имеет. Но убедить рекламодателя в этом абстрактными аргументами сложно. Поэтому это исследование — на цифрах, на сырых данных одного из аккаунтов, почему такая структура сейчас вредит.
В аккаунте, который я недавно приняла на аудит, я заметила знакомую картину: один и тот же идентификатор товара показывался в двух разных PMax-кампаниях одновременно. Рядом с родным айдишником SKU_25570 в отчете стоял df_SKU_25570 — тот же товар, но с модифицированным ID из-за дублирования фида в Merchant Center. Две Performance Max-кампании видели один SKU, обе крутили на нем рекламу.
Этот паттерн распространен в e-commerce кабинетах. Аккаунт-менеджеры сознательно создают «дубликат фида» с префиксом df_ именно для того, чтобы обойти техническое ограничение «один SKU = одна кампания» и запустить вторую PMax на ту же товарную позицию. В индустрии существуют три типичные оправдания, почему это делают:
- Сегментация аудиторий — мол, две кампании «ловят» разные сегменты покупателей: одна тех, кто ищет дешевле, другая — более дорогих клиентов.
- Хеджирование рисков — если алгоритм в одной кампании «сломается» или потеряет обучение, вторая подстрахует.
- Скрытый A/B-тест — сравнить разные tROAS, разные audience signals, разные наборы assets на тех же товарах.
Каждое из этих оправданий звучит рационально. Но они основаны на предположениях о том, как на самом деле ведет себя алгоритм Performance Max, когда сталкивается с двумя кампаниями одного аккаунта, конкурирующими за один SKU. Я хотела проверить это на сырых данных.
Вопрос исследования был простым: каннибализируют ли две PMax на один товар друг друга на аукционе? Если да — как именно и сколько это стоит? Если нет — возможно, этот паттерн на самом деле полезен для бизнеса?
Спойлер: ответ оказался сложнее, чем любой из трех сценариев, которые я ожидала.
Данные и методология
Исследование проведено на e-commerce аккаунте в категории товаров для дома. Период данных — 16 месяцев: 30 декабря 2024 → 20 апреля 2026. Я не буду вести этот аккаунт публично, поэтому вместо названий реальных кампаний использую нейтральные обозначения: PMax A — старая кампания, работала весь период; PMax B — новая, стартовала в середине периода.
Данные
Выгрузка из Google Ads была сделана в пять отдельных экспортов из-за лимита строк Google Ads. Объединила и очистила:
- Отчет по товарам в Покупках — 1.65 миллиона строк. Сегментация: кампания × неделя × ID товара. 22 PMax-кампании, из них на анализ пошло три. ~30,000 уникальных SKU.
- Отчет по поисковым запросам — 2.24 миллиона строк. Тот же период и те же три кампании. 245,000 уникальных поисковых запросов.
- История изменений кампаний — 986 записей изменений tROAS, бюджетов, статусов за 16 месяцев. Критически важно для контроля конфаундеров.
Числа я очистила от европейской локали (десятичная запятая, пробелы в числах, кавычки), нормализовала item_id (срезала префикс df_ от дубликатов фида), отфильтровала только те SKU, которые принадлежат анализируемому домену (89.8% всех строк — остальное выбросила как товары других сайтов кабинета).
Методологические ловушки, которые я закрыла
Это мое четвертое исследование PMax-алгоритма на сырых данных. В предыдущих трех я наступила на четыре ловушки, которые разрушили первые выводы. Здесь я закрывала их осознанно еще до запуска анализа:
Ловушка 1 — формат item_id
ID товаров в двух фидах могут иметь разные префиксы. В моем случае 4,642 из 9,631 SKU имели префикс df_ (дубликат фида). Без нормализации матчинг shared SKU давал бы 12% вместо реальных 50%. Проверка: для всех 2,375 SKU, которые имели обе версии, Merchant Center ID у df_X и X совпадает. То есть df_X и X — это один и тот же товар из одного MC, только с модифицированным ID.
Ловушка 2 — selection bias
Если группировать SKU по их активности после стартового события — Google сам выбирает топ-SKU для второй кампании, и «эффект кампании» оказывается selection bias. Я фиксирую группы SKU по pre-period активности (до момента старта второй кампании), а затем смотрю, как каждая группа ведет себя после.
Ловушка 3 — конфаундеры из истории изменений
Конфаундер — это фактор, который меняется параллельно с тем, что мы исследуем, и из-за этого может создать иллюзию причинно-следственной связи. Простой пример: если я хочу измерить эффект старта второй PMax на CPC, и именно в эту же неделю я подняла tROAS в первой кампании — скачок CPC можно списать на что угодно из этих двух изменений. Это и есть конфаундер.
Любое изменение tROAS, бюджета, фильтра товаров за период анализа создает конфаундер. Я извлекла полную change history по всем трем кампаниям. Результат показал 89 критических изменений (tROAS, бюджет, статус) за 17 месяцев в одной паре. В окне ±6 недель вокруг стартового события — 40 изменений. Это не «чистый природный эксперимент», и это нужно честно признать.
Ловушка 4 — life cycle товаров
В предыдущем исследовании топ-50 SKU оказались конкретным жанровым трендом, который естественно остывал. «Просадка PMax» выглядела как алгоритмический эффект, но была demand cycle. Прежде чем делать выводы, я посмотрела на топ-20 shared SKU по конверсиям — это evergreen-каталог декора для стен с постоянным спросом, не сезонные позиции.
Дизайн исследования
Я сосредоточилась на двух парах кампаний с наибольшими расходами на shared SKU:
- Пара A (longitudinal): PMax A (старая, работала >12 месяцев) и PMax B (новая, стартовала в середине периода). 21 неделя общей истории. Reference event = неделя старта PMax B. Позволяет сравнить «до» и «после» появления второй кампании.
- Пара B (cross-sectional): PMax A и еще одна старая кампания, которая работала весь период. 68 недель общей истории. Здесь нет ref event — сравниваю shared vs solo SKU внутри периода. Служит как проверка выводов из пары A на независимых данных.
Третий тестовый кандидат на longitudinal-сравнение оказался непригодным — кампания работала на другом формате ID (без характерного суффикса домена), поэтому SKU не матчились с нашими. Выбросила.
Один из ключевых методологических выборов — сравниваю только одни и те же юниты. Не «shared SKU vs solo SKU» (это разные группы товаров с разными характеристиками), а «тот же SKU в двух кампаниях в ту же неделю». Это закрывает третий важный слой selection bias.
Инсайт 1: две PMax поднимают ставку друг другу на тех же запросах
Первое, что я хотела выяснить — ловят ли кампании вообще одни и те же поисковые запросы. Может, Google внутри разводит их на разные аукционы (одна на категорийные запросы, другая на бренд, например)? Если так — каннибализации нет по определению.
Я посчитала пересечение поисковых запросов между PMax A и PMax B в post-period — после того, как вторая кампания стартовала. Результат:
- Уникальных поисковых запросов в PMax A: 88,027;
- Уникальных поисковых запросов в PMax B: 35,496;
- Пересечение: 31,552 — это 88.9% от меньшей кампании.
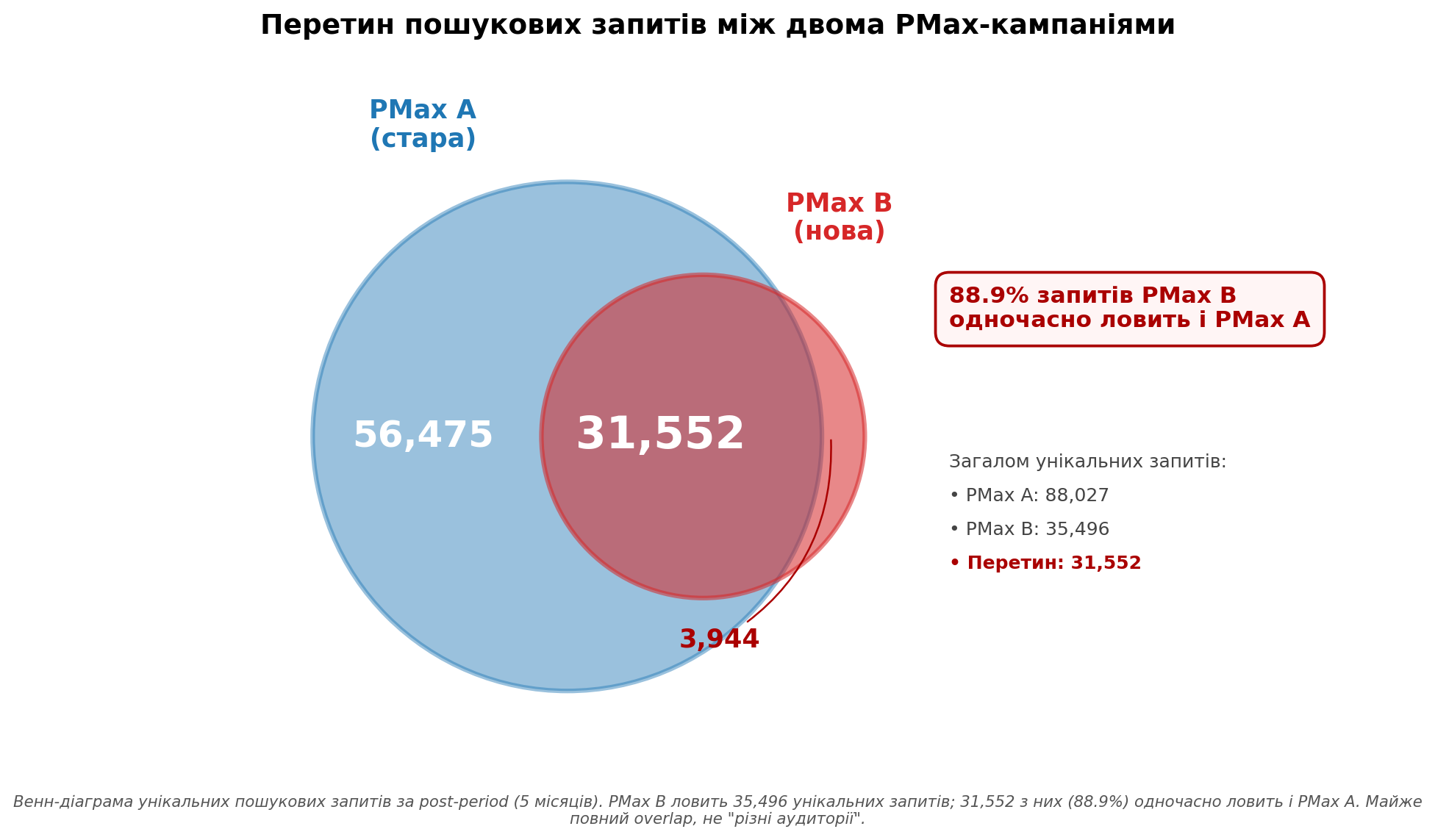
График 1. Диаграмма Венна пересечения поисковых запросов. Почти все запросы, которые ловит PMax B, одновременно ловит и PMax A.
88.9% запросов, которые ловит PMax B, одновременно ловит и PMax A. Это не «разные аудитории» — это почти полное пересечение. Гипотеза, что Google разводит кампании на уровне запросов, отвергается.
Далее — главный тест. На запросах, где обе кампании получили клик в той же неделе, я сравнила CPC. Если алгоритм Performance Max эффективно разводит кампании на уровне аукциона — CPC в двух кампаниях должен быть примерно одинаковым. Если они конкурируют друг с другом — ставка более слабой будет выше.
Что показывает CPC на overlap-запросах?
4,386 пар «запрос × неделя», где обе кампании получили клик. Взвешенный CPC (взвешен по кликам):
- PMax A: 1.73 PLN;
- PMax B: 3.01 PLN;
- Разница: PMax B на 74% дороже.
На 58% наблюдений PMax B дороже PMax A за тот же клик. Распределение неравномерное — в хвосте (P90) PMax B платит в 3.6 раза дороже, в P95 — в 6 раз дороже. Это не «шум». Это четкий паттерн bid escalation: когда два бидера одного аккаунта лезут в один аукцион, ставка поднимается.
Еще интереснее — как этот паттерн зависит от объема запроса. Я разбила overlap-запросы на 5 сегментов по количеству кликов, которые получила PMax B:
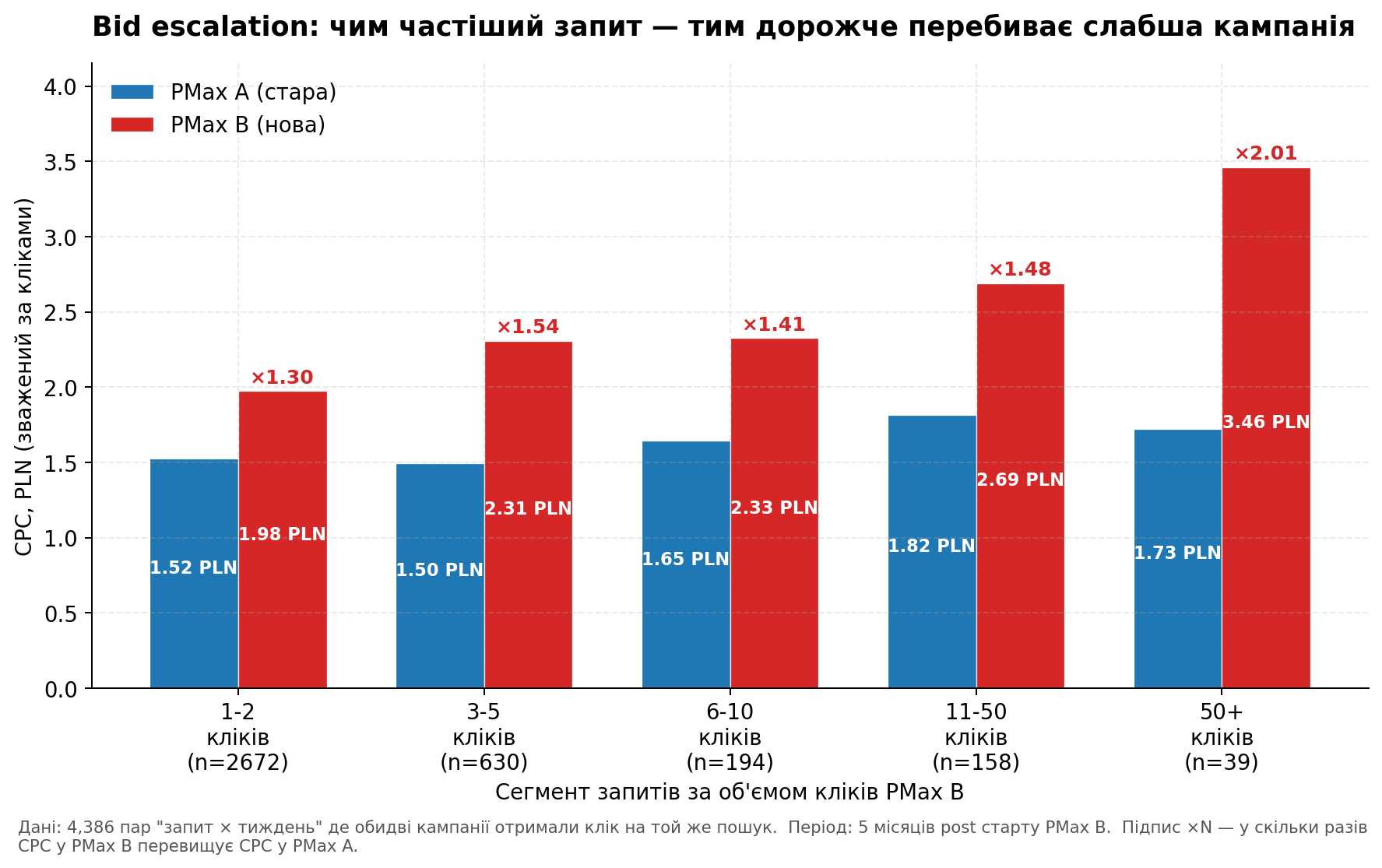
График 2. Bid escalation по объему запросов. На редких запросах (1-2 клика) PMax B платит +30%; на топ-запросах (50+) — в 2 раза дороже.
Чем интенсивнее аукцион, тем выше налог за двойное участие. На редких запросах (1-2 клика в неделю) PMax B переплачивает умеренно — +30%. На средних — +40-55%. На топ-запросах, где идет много трафика (50+ кликов на запрос в неделю), PMax B платит уже в 2 раза дороже PMax A.
Что я имею в виду под «налогом за двойное участие». Когда в одном аукционе Google две кампании одного аккаунта, алгоритм должен выбрать между ними — и делает это через поднятие ставки. В результате обе кампании заплатят больше, чем заплатил бы один участник. Эта надбавка — и есть налог: деньги, которые аккаунт отдает Google исключительно за факт того, что у него в системе две кампании на тот же товар, а не одна.
Это классическая экономика аукциона: когда в аукционе одна сторона с агрессивной ставкой, вторая вынуждена поднимать свою, чтобы не исчезнуть из показов. В обычных условиях это механизм ценообразования между независимыми рекламодателями. Здесь это механизм ценообразования между двумя кампаниями одной и той же компании, у которых нет никаких причин конкурировать друг с другом — кроме того, что они существуют параллельно.
Вывод 1: чем чаще поисковый запрос, тем сильнее каннибализация. На топ-запросах CPC более слабой кампании достигает 2x. Это не «Google разводит кампании на разные запросы» — это Google пускает обе в тот же аукцион и собирает более высокую ставку.
Почему это совпадает с тем, что видят практики?
Из моей практики: типичное поведение PMax — если в аккаунте крутится сильный товар в двух PMax-кампаниях, одна из них всегда дороже. Я вижу это постоянно. Bid escalation — феномен, который практики PPC видят на своих аккаунтах годами. Просто теперь он измерен.
Вторая важная деталь — PMax не изолирует кампании на уровне поисковых запросов. В документации Google написано прямо: алгоритм учитывает сигналы со всего аккаунта, когда решает, какой запрос назначить какому объекту. То есть две PMax — это не «две воронки» с собственными воронками запросов, а две нити одной матрицы. И в тех местах, где эти нити пересекаются — алгоритм поднимает ставку до того уровня, который обе готовы платить.
Инсайт 2: миф о сегментации аудиторий
Самое распространенное оправдание двух PMax — «одна ловит дешевых клиентов, вторая — дорогих, аудитории разделены». Это звучит убедительно: если PMax B ловит клиентов с более высоким средним чеком, то даже переплата за CPC оправдана — value больше.
На своих первых итерациях анализа я была близка к подтверждению этого тезиса. В PMax B на overlap-запросах AOV (средний чек на конверсию) оказался 1,150 PLN против 707 PLN в PMax A. Почти в 1.6 раза выше. Я даже на минуту подумала, что нашла положительный эффект дублирования — «PMax B ловит более дорогих клиентов».
Но я пошла глубже и нашла нюанс. Общее среднее AOV скрывало распределение по объему запросов. Если посчитать отдельно по сегментам — картина может оказаться совершенно иной.
Я разбила overlap-запросы по volume bucket и посмотрела AOV в каждом:
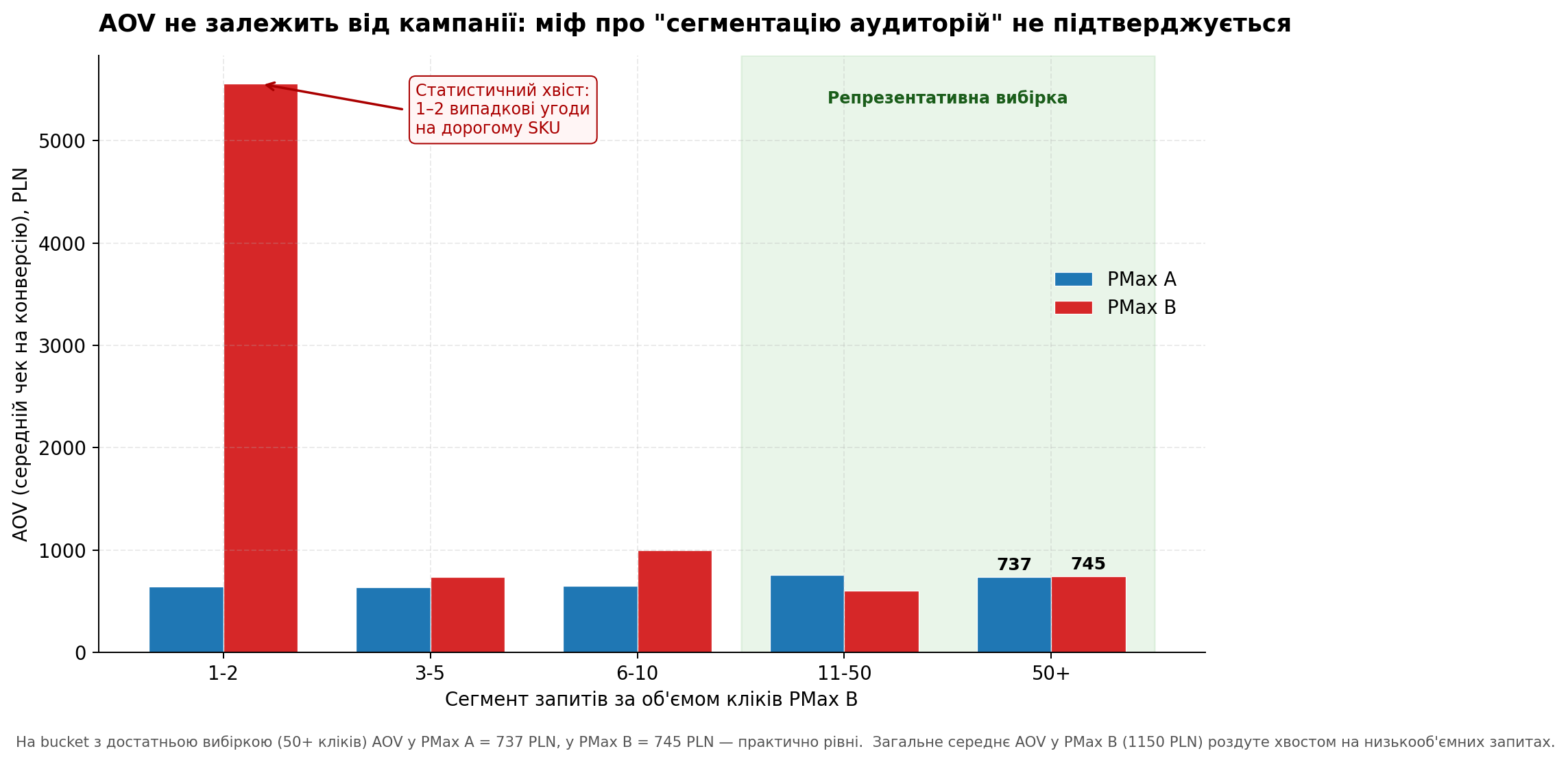
График 3. AOV по сегментам запросов. На репрезентативной выборке (50+ кликов) AOV в двух кампаниях практически равен.
Картина полностью изменилась. В bucket с достаточной выборкой (50+ кликов — наиболее репрезентативный сегмент) AOV в PMax A = 737 PLN, в PMax B = 745 PLN. Практически равны.
Общее среднее AOV = 1,150 PLN в PMax B оказалось полностью результатом хвоста в bucket 1-2 клика. Там одна-две случайные сделки на дорогом SKU (средний чек ~5,500 PLN) раздули среднее по группе. Если выкинуть этот хвост — никакой реальной «сегментации аудиторий по чеку» между двумя PMax нет.
Вывод 2: миф о «сегментации на дорогих и дешевых клиентов» не подтверждается. AOV выравнивается до среднего по нише независимо от того, какая из двух PMax-кампаний поймала покупателя.
Это методологически важный момент. В статистике есть известный эффект: на маленькой выборке среднее всегда будет нестабильным. Один крупный заказчик на 5,000 PLN превращает группу из 10 кликов в «сегмент с высоким AOV». Если менеджер посмотрит на агрегированную цифру по PMax B — увидит мнимое преимущество. Если посмотрит на распределение по сегментам — увидит, что это артефакт.
Это и есть фундаментальная проблема того, как PPC-специалисты часто оценивают кампании: «среднее AOV в кампании X». Когда кампания имеет неравномерное распределение объема между запросами (а в PMax это почти всегда так — 80/20), среднее по кампании не репрезентативно. Оно взвешено именно хвостом.
Что это означает для теории «разных аудиторий»?
Если AOV одинаковый, два логических вывода:
- Performance Max не «сегментирует» клиентов по платежеспособности. Алгоритм внутри того же поискового запроса («категорийный запрос») направляет трафик в разные кампании, но не по «типу покупателя», а по другим сигналам (audience signals в кампании, креативы в asset groups, landing page). Сам пул аудиторий, который видит каждая кампания — одинаковый.
- Это означает, что в двух PMax нет реальной «продуктовой логики» сегментации — есть только искусственная, через дублирование фида. В результате две кампании конкурируют за тот же пул покупателей с теми же средними чеками — просто с разными наборами assets.
Это тот момент, где теория «полезного дублирования» разваливается. Если AOV одинаковый, тогда все, что происходит — это bid escalation из Вывода 1, который не приносит дополнительной value, только увеличивает расходы аккаунта.
Инсайт 3: реальный CPA на покупателя завышен на 21%
Здесь я сделала самую серьезную методологическую ошибку в первых итерациях, и вот как ее пришлось исправлять.
Сначала я посчитала CPA отдельно в каждой кампании на overlap-запросах:
- CPA в PMax A на overlap: 340 PLN;
- CPA в PMax B на overlap: 334 PLN.
«Почти одинаковый». Я сделала вывод, что две кампании экономически нейтральны — переплата за CPC в PMax B (+74%) компенсируется более высоким CR (вдвое), и в итоге стоимость привлечения покупателя одинакова. Дублирование казалось бесплатным.
Но смотреть на CPA так — как на простой показатель отдельной кампании — некорректно для нашего случая. Я смотрела на CPA так, будто клиент зашел с одного клика и сразу купил. Но на самом деле в этом аккаунте атрибуционный путь — 3.5 взаимодействия / 2.6 дня до покупки. То есть на одну конверсию приходится в среднем 3.5 клика. И когда в аккаунте две PMax-кампании на те же поисковые запросы, эти 3.5 клика разбросаны между двумя кампаниями. Здесь нужно считать не CPA отдельной кампании, а CPA на покупателя в сумме.
Представим реальный путь клиента: он видит рекламу по запросу «категорийный запрос + спецификатор» и кликает (PMax A). Через день ищет снова по запросу «категорийный запрос + помещение» и кликает (PMax B). Еще через день ищет бренд и кликает снова (PMax A). Потом покупает. Кто «привел» эту конверсию? В data-driven attribution — оба. Каждая кампания записывает себе часть конверсии. В отчетах: PMax A заплатила 5 PLN за ту конверсию, PMax B заплатила 6 PLN, каждая показывает адекватный CPA.
Но реальная стоимость конверсии = 11 PLN. Это сумма того, что две кампании заплатили, чтобы привести одного покупателя. И это число нигде в отчете Google Ads не видно.
Как я посчитала реальный CPA?
На overlap-запросах за 5 месяцев post-period:
Метрика | Значение |
Суммарные расходы (PMax A + PMax B) | 116,233 PLN |
Суммарные конверсии (обеих кампаний) | 494 |
Реальный CPA на покупателя | 235 PLN |
Суммарная value (обеих кампаний) | 427,514 PLN |
Суммарный ROAS | 3.68 |
Реальный CPA = 235 PLN. Не 340 и не 334, которые видны в отчетах. 235.
Теперь контрфактное сравнение. Что было бы, если бы только PMax A ловила эти запросы? Конверсии все равно бы произошли — клиент ищет категорийный запрос на том же сайте, с тем же товарным каталогом. Он бы кликнул по PMax A вместо PMax B на одном из шагов пути и пришел к той же покупке. Расходы были бы ниже, потому что CPC в PMax A на overlap-запросах = 1.73 PLN, тогда как в PMax B = 3.01 PLN.
Расчет:
- Суммарные клики overlap: 51,428;
- CPC в PMax A на overlap: 1.87 PLN;
- Контрфактный cost (все клики по CPC PMax A): 95,996 PLN;
- Конверсии (предполагаем те же): 494;
- Контрфактный CPA: 194 PLN.
Разница между фактическим и контрфактным CPA = 41 PLN на каждую конверсию. В процентах — 21% завышения.
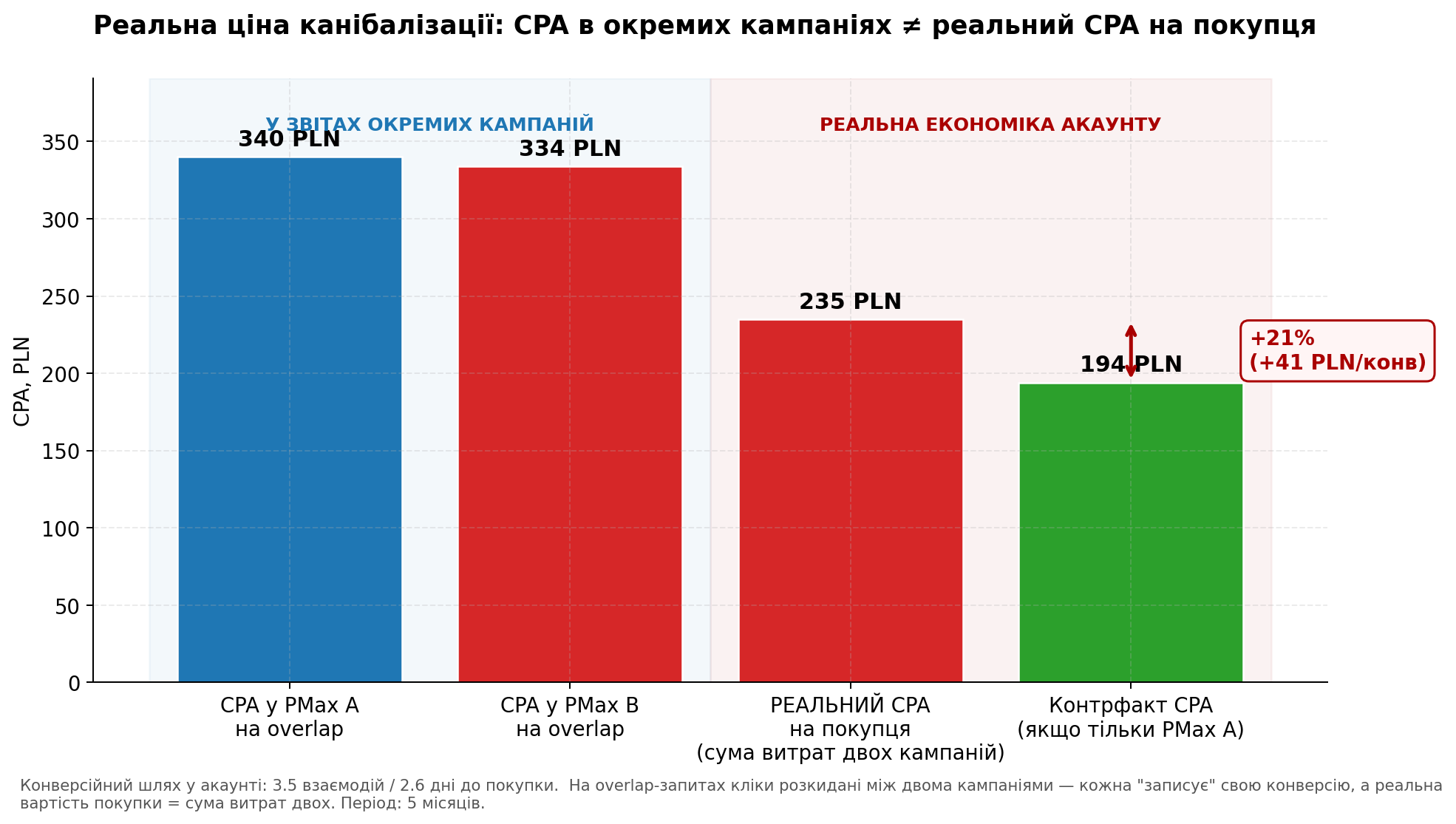
График 4. CPA в отдельных кампаниях (340 и 334 PLN) выглядит одинаковым. Реальный CPA на покупателя, с учетом суммарных расходов двух кампаний — 235 PLN. Контрфакт без дублирования — 194 PLN. Разница +21%.
Вывод 3: каннибализация завышает реальный CPA на покупателя на 21%. В отчетах отдельных кампаний этого не видно — там показатели выглядят нормальными. Завышение заметно только если считать суммарную экономику аккаунта по ключевым SKU.
Почему эта ошибка так типична?
Я делаю эту ошибку не одна. Это базовый способ смотреть на эффективность кампаний: открыл отчет по кампании — увидел CPA. Если CPA в пределах KPI — кампания здорова.
Но это работает только когда кампании независимы. Если они делят одну и ту же базу клиентов — каждая показывает «свою» часть тех же конверсий, и CPA индивидуально выглядит честным. Сумма же расходов на одного реального покупателя — невидима.
Чем короче атрибуционный путь, тем менее заметен эффект. Если в аккаунте атрибуция 1.2 взаимодействия на конверсию — переплата будет ~5%. Если 3.5 — как в нашем случае, 21%. Если 5+ — может быть 35%+.
На маленьких бюджетах и сложных путях конверсии удорожание даже больше 21%. Две PMax-кампании на одну и ту же нишу зашивают в CPA скрытую надбавку, которую аккаунт-менеджер не видит — потому что в отдельной кампании показатели выглядят нормально.
Суммарная переплата во времени
Я посчитала недельную переплату на overlap-запросах. Формула: cost_PMax_B − (clicks_PMax_B × CPC_PMax_A на том же запросе). То есть сколько PMax B заплатил сверх того, что PMax A заплатила бы за те же клики.
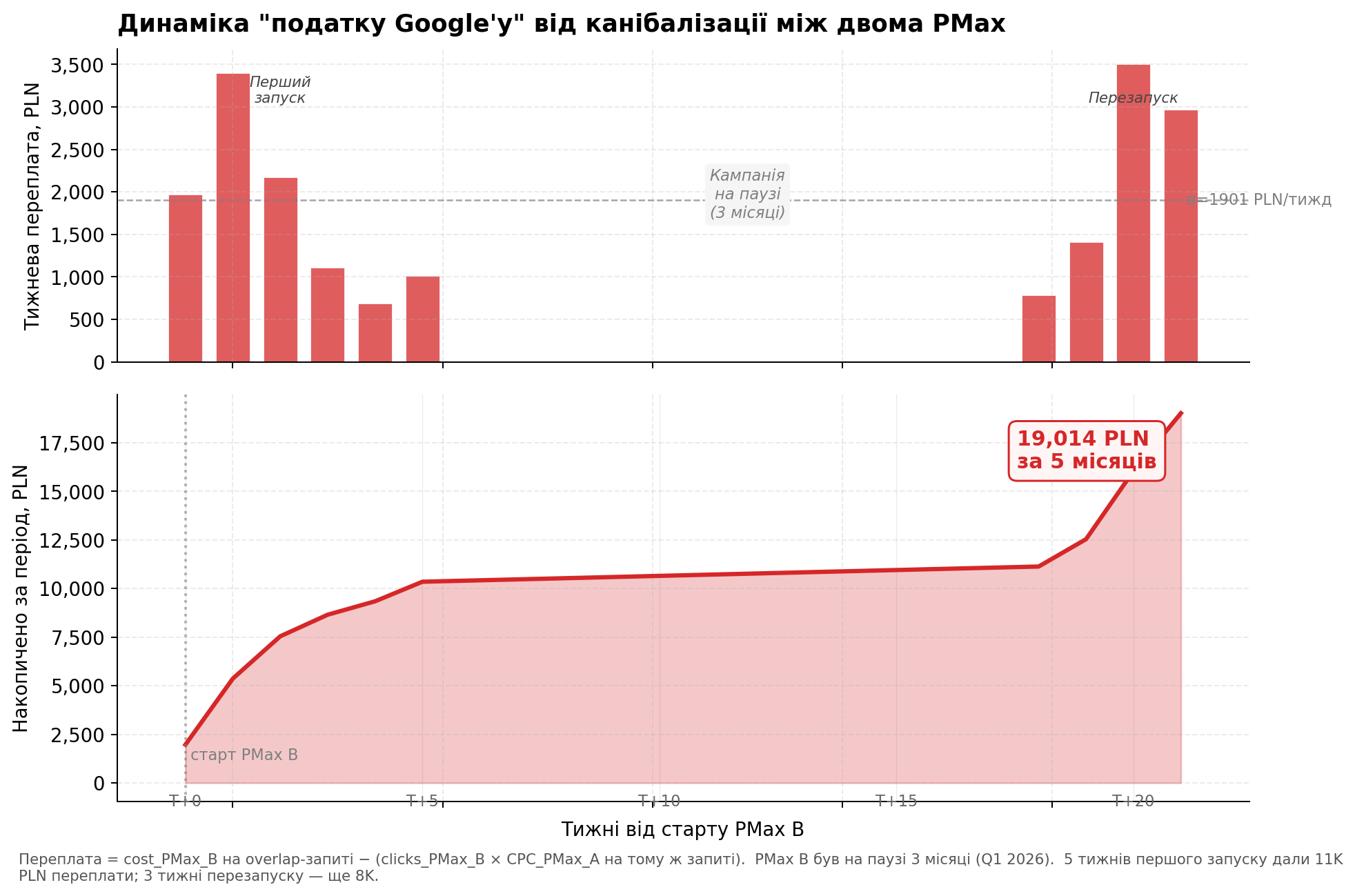
График 5. Недельная переплата (сверху) и накопленная сумма (снизу). PMax B был на паузе ~3 месяца посередине периода — поэтому накопленная кривая имеет плато.
Суммарная переплата за 5 месяцев post-period = 19,014 PLN. Это чистые деньги, переданные Google из-за того, что две кампании одного аккаунта поднимали ставку друг другу.
Интересный паттерн на графике: переплата шла только в первые 5 недель запуска, потом стихла, потом вспыхнула снова после перезапуска PMax B в апреле. Между ними — 3 месяца паузы, когда кампания B не была активна. Это подтверждает, что эффект не «артефакт данных» — он прямо коррелирует с тем, когда вторая кампания работает.
Проекция на год: ~45,000 PLN избыточных расходов. На один аккаунт. На одну пару кампаний. На этом же аккаунте есть другие пары с overlap, которые я не анализировала глубоко — реальная цифра по всему аккаунту скорее всего выше.
Как это работает технически?
Осталось объяснить механику. Почему две PMax-кампании одного аккаунта вообще конкурируют между собой на аукционе? Разве Google не должен их «разводить»?
Ответ — и да и нет. Google разводит показы, но не CPC. Избирательность видна в самих числах: на overlap-запросах PMax A забирает 95% показов и конверсий, PMax B — 5%. То есть система не пропускает обе кампании в тот же показ параллельно — только одна появляется на конкретном импрессии.
Но CPC это распределение не компенсирует. Аукцион Google работает так, что ставка кампании зависит от конкуренции и ее tROAS. Когда PMax B выходит на высокообъемный запрос с агрессивной ставкой (Google стремится потратить ее бюджет на лучшие позиции), она заставляет PMax A тоже поднимать ставку — иначе PMax A перестанет появляться. В результате обе платят больше, чем заплатили бы, если бы не конкурировали.
Интересно посмотреть на топ-15 запросов, которые приносят наибольшую абсолютную переплату:
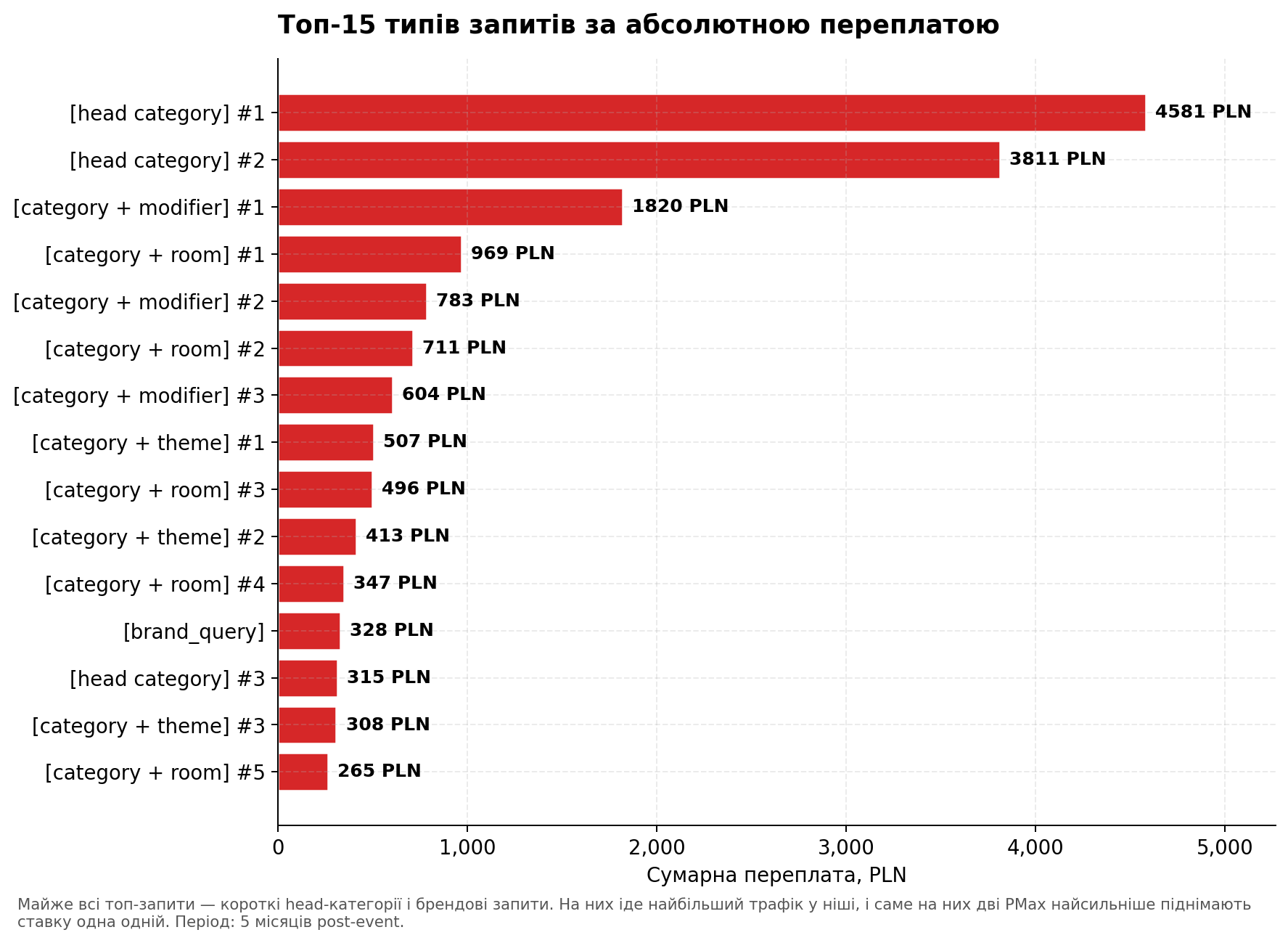
График 6. Топ-15 типов поисковых запросов по переплате. Почти все — короткие head-категории и брендовые запросы.
Почти все топ-запросы — короткие обобщенные head-категории и бренд. На них идет наибольший трафик в нише, и именно на них алгоритм сильнее всего поднимает ставку. На long-tail запросах эффект слабее — там аукционная плотность ниже, и интерференция менее заметна.
Это совпадает с логикой Вывода 1 — bid escalation растет с объемом запроса. На редких long-tail запросах PMax B переплачивает умеренно (+30%). На дорогих head-запросах — в 2 раза. В итоге основная сумма переплаты концентрируется именно на тех 10-15 запросах, которые приносят наибольший объем трафика.
Что говорит документация Google?
В официальной справке Google прямо указано, что PMax учитывает сигналы со всего аккаунта. В официальном анонсе Performance Max с 2021 года: «Performance Max uses your campaign goals, audience signals, and assets across the account to find new conversion opportunities.» То есть алгоритм намеренно смотрит на широкую картину аккаунта, не изолирует каждую кампанию в свою воронку.
На практике это означает: две PMax-кампании одного аккаунта, даже с разными фидами, даже с разными audience signals — это не «две независимые системы». Это две ветви одной матрицы, которая внутри конкурирует за бюджет, конверсии и показы. Дублирование item_id через df_ префикс не обходит эту архитектуру — только делает интерференцию более заметной.
Выводы
Исследование дало три основных вывода и одно обобщение:
Каннибализация на аукционе есть и измерена
На поисковых запросах, где обе PMax активны, более слабая кампания платит на 30-100% дороже за клик, в зависимости от интенсивности аукциона. На топ-запросах — в 2 раза дороже. 88.9% запросов, которые ловит вторая кампания, одновременно ловит и первая.
«Сегментация аудиторий» — миф
AOV одинаковый в двух кампаниях, если считать на репрезентативной выборке. Общее среднее может казаться разным только из-за хвостовой неравномерности распределения — артефакт малых чисел, не реальная сегментация. Оправдание «одна ловит дешевых, другая дорогих» не подтверждается.
Реальный CPA завышен на 21%
Из-за атрибуционного пути в 3.5 взаимодействия на конверсию, две кампании распределяют между собой клики одного и того же покупателя. В отчетах отдельных кампаний CPA выглядит нормальным (340 и 334 PLN). Реальный CPA на покупателя = 235 PLN. Контрфакт без дублирования = 194 PLN. Завышение на 21% (+41 PLN на конверсию).
Две PMax-кампании на один и тот же товарный фид — это не «хеджирование» и не «AB-тест». Это структурный налог Google. На поисковом запросе, где обе активны, CPC более слабой растет на 30-100%. Никакой реальной сегментации аудиторий между кампаниями нет. Суммарный CPA аккаунта завышен на 20%+. В отчетах отдельных кампаний это невидимо. Только суммарная экономика аккаунта по ключевым SKU выявляет паттерн.
Ограничения исследования
Честно о слабых сторонах:
- Одна пара кампаний, одна ниша. Выводы могут отличаться для других ниш или других структур аккаунта. Репликация на 5-10 аккаунтах разных ниш дала бы более робастную картину.
- Контрфакт — предположение. Я предполагаю, что без PMax B все конверсии все равно пришли бы через PMax A. Это правдоподобно, но не доказано. Чистый тест — A/B с отключением PMax B на 4 недели.
- Конфаундеры в change history. 89 критических изменений tROAS и бюджета за период нарушают условие «all else equal». Longitudinal-вывод из пары A на этом аккаунте частично скомпрометирован. Cross-sectional на паре B остается валидным.
- Не анализирую второстепенные пары. Топ-3 пары по overlap сосредоточены вокруг одной большой кампании (PMax A). Возможно, в парах без ее участия паттерн другой. Это следующий шаг исследования.
Открытые вопросы
Исследование не дало ответа на:
- Одинаково ли сильна каннибализация на аккаунтах с более коротким атрибуционным путем (1.5-2 взаимодействия на конверсию). Гипотеза — слабее, потому что меньше шансов на повторные клики.
- Можно ли уменьшить каннибализацию через жесткие audience signals или негативные keywords (хотя в PMax нет прямых негативных keywords).
- Как ведет себя вторая PMax на аккаунтах, где первая имеет очень маленький бюджет — возможен ли обратный эффект, когда вторая кампания «тянет» за собой первую.
- Как выглядит аналогичный анализ для Standard Shopping + PMax вместо PMax + PMax.
Это материал для будущих частей серии исследований PMax-алгоритма.
FAQ
-
Не всегда, но в подавляющем большинстве случаев сейчас — да. Исключение — кейсы, когда две кампании реально имеют разную экономическую логику: разные страны, разные языки, разные этапы воронки (например, одна на новых клиентов, другая на ремаркетинг). В таких случаях overlap естественно низкий, и каннибализации не возникает. В e-commerce кабинете, где обе PMax таргетятся на ту же рыночную нишу и тот же товарный фид — overlap будет около 90%, как в этом исследовании, и дублирование вредит.
-
Самый простой способ — открыть отчет «Товары → Статус в каждой кампании» в Google Ads UI. Если увидите, что тот же item_id «пригоден в стольких кампаниях: 2, 3, 6» и это PMax-кампании — у вас точно есть overlap. Более глубокая проверка — экспортировать отчет по поисковым запросам за период, когда обе кампании активны, и посмотреть, сколько запросов общих. Если overlap >50% от меньшей кампании и она показала заметный объем трафика — каннибализация почти гарантирована.
-
Документация Google не запрещает дублирование, но и не рекомендует. В ней прямо указано, что PMax учитывает сигналы со всего аккаунта — то есть Google знает об архитектурных последствиях, но не обязан предупреждать об экономических. Что логично: переплата за двойное участие — это доход Google, не его проблема. Алгоритм технически делает то, что от него просят (показываться на том SKU в двух кампаниях), просто с более высокой суммарной ценой за результат.
-
Если цель — разделить кампании на разные товарные группы без overlap, custom_label сегментация эффективна. Один SKU попадает только в одну кампанию по правилу — и каннибализации нет по определению. Если цель — дублировать SKU в двух кампаниях через
df_префикс притом, что custom_label не используется для разделения — сегментация не помогает, потому что она не активна. В исследовании я не анализировала аккаунт с custom_label архитектурой — это отдельный вопрос для будущей статьи. -
Да, сильнее. На аккаунтах с малым бюджетом кампании чаще упираются в лимит — и когда так происходит, аукционная динамика искажается: алгоритм агрессивнее торгуется, чтобы успеть потратить бюджет до конца дня. Две малобюджетные PMax на те же товары создают более сильный bid escalation, чем две хорошо забюджетированные. Плюс на малых бюджетах каждая дополнительная конверсия стоит дороже из-за эффекта learning phase — который начинается заново при каждом перезапуске. В этом исследовании я работаю с аккаунтом среднего размера, поэтому 21% — это скорее нижняя граница эффекта, не верхняя.
-
Лучшее — показать клиенту цифры. Этот текст и написан для того, чтобы конкретный кейс можно было использовать как аргумент. Если клиент продолжает настаивать, вариант «мягкого» решения — сделать кампании максимально разными по всем остальным параметрам: разные товарные группы через listing groups (минимум overlap по SKU), разные цели тендера (одна на ROAS, другая на conversions), разные landing pages. Это не полностью устраняет каннибализацию, но минимизирует ее. Жесткое решение — поставить A/B тест: отключить одну из кампаний на 2-3 недели и измерить, ухудшился ли суммарный CPA аккаунта. Если нет — решение принимает себя.